Construire un Agent IA facilement grâce à l'AI SDK
Fait partie de la série Agents IA et serveur MCP au service du web agentique
Avant d'aller plus loin, qu'est-ce qu'un Agent IA ? Je pense qu'il est important de clarifier ce concept afin que nous ayons une meilleure compréhension de ce que nous essayons de faire.
Un Agent IA est un logiciel qui utilise l'IA pour effectuer des tâches au nom d'un utilisateur. Cela signifie que vous pouvez lui demander quelque chose en langage naturel, texte ou voix, et il comprendra puis effectuera la tâche en conséquence. C'est un énorme pas vers des interactions plus naturelles et intuitives avec les machines.
Vous n'avez pas besoin de savoir précisément ce que vous cherchez ou ce que vous voulez effectuer. L'Agent IA peut comprendre une suite d'actions dans une même requête, ce qui est nouveau. Jusqu'à présent, des assistants comme Siri ou Google Assistant demandaient des commandes plus spécifiques et ne pouvaient gérer qu'une action à la fois. Par exemple, "Démarrer un minuteur et ajouter un élément à la liste" nécessitait auparavant des commandes séparées.
Fonctionnalités de l'IA
Pour y voir plus clair, passons en revue les capacités actuelles de l'IA. Pour être précis, nous allons nous concentrer sur les LLM qui génèrent du texte à partir d'une entrée textuelle ; cela garde la série lisible sans en réduire la pertinence.
- Génère du texte à partir de l'entrée fournie.
- Raisonne sur le contexte pour augmenter la pertinence et la cohérence.
- Appelle des outils pour agir dans le monde réel.
Note
Selon le provider, des fonctionnalités supplémentaires peuvent être disponibles, comme des outils intégrés ou des outils MCP. En fin de compte, tout est considéré comme un outil, qu'il s'agisse d'une fonction intégrée, d'une API externe via MCP ou d'un outil personnalisé.
Lorsque vous interagissez avec une IA, elle utilise une ou plusieurs de ces capacités pour répondre à votre demande. Cependant, il y a des points importants à noter.
Le raisonnement intervient toujours avant la réponse de l'IA. Cela signifie que si l'IA raisonne, elle va ensuite soit générer du texte (capacité 1), soit appeler un outil (capacité 3).
De plus, les modèles les plus récents peuvent appeler plusieurs outils dans une seule requête, et générer du texte avant et entre les appels d'outils pour informer l'utilisateur de l'avancement.
Cela signifie que si l'IA choisit d'appeler des outils, l'utilisateur ne recevra pas de réponse immédiate, car la capacité de génération de texte n'est pas utilisée. Si l'utilisateur doit ensuite relancer l'IA avec "Puis-je avoir ma réponse ?", le chat que nous voulions construire ne sera pas viable.
Note
Il est important de noter que l'IA n'exécute pas directement les outils personnalisés. Elle demande au client, via une réponse dédiée, d'appeler l'outil pour elle. C'est pourquoi définir des outils revient souvent à définir un schéma JSON. Je recommande de lire le flux d'appel d'outils dans la documentation OpenAI.
Boucler sur elle-même
Pour résoudre ce problème, nous pouvons implémenter une fonctionnalité simple mais puissante : une boucle.
Oui, une simple boucle while rend notre interface de chat réalisable. Si la réponse est un appel d'outil, nous pouvons boucler jusqu'à obtenir une réponse textuelle.
Avec un peu de pseudo-code, cela ressemble à :
while (true) {
response = AI.ask(userInput)
if (response.isText()) {
break
}
// Call the tool and update the user
}C'est tout. Cette simple boucle, combinée aux trois capacités d'IA définies plus haut, correspond à ce que nous appelons un Agent IA. Tant que la réponse n'est pas une génération de texte directe, il y a quand même raisonnement et utilisation d'outils.
Note
Pour éviter une boucle infinie, définissez un nombre maximal d'itérations.
Notre Agent
Je pense que nous sommes prêts à commencer à construire notre Agent IA.
Pour cette série, nous allons utiliser l'AI SDK. Nous aurions pu utiliser un SDK fourni par un prestataire comme OpenAI ou Anthropic, mais le niveau d'abstraction plus élevé de l'AI SDK nous facilitera la tâche tout en évitant l'enfermement fournisseur.
Pour nous assurer que nous sommes tous sur la même longueur d'onde, voici un aperçu de l'infrastructure que nous construisons.
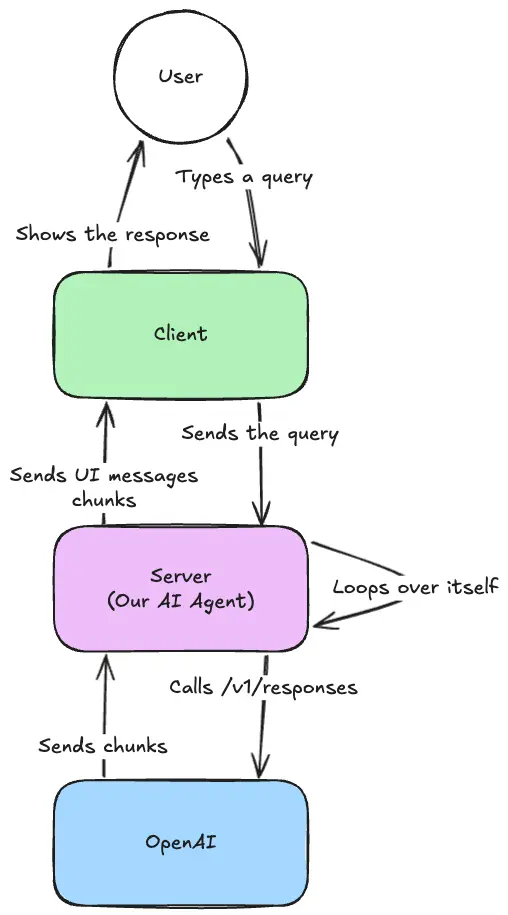
Pour cette partie, nous allons nous concentrer sur l'implémentation côté serveur et la communication avec le fournisseur.
Pour cela, nous utiliserons Nitro, mais vous pouvez utiliser n'importe quel framework backend JS de votre choix.
Installation
Créez d'abord un nouveau projet Nitro :
pnpm dlx giget@latest nitro ai-agent --installPuis supprimez le fichier server/routes/index.ts, dont nous n'aurons pas besoin :
rm server/routes/index.tsDémarrer avec l'AI SDK
Maintenant que notre backend est en place, nous pouvons commencer à travailler avec l'AI SDK.
Installez le SDK :
pnpm add ai @ai-sdk/openaiNous installons aussi l'adaptateur OpenAI pour communiquer avec l'API OpenAI, mais vous pouvez utiliser n'importe quel autre adaptateur que vous préférez.
Pour communiquer avec OpenAI, configurez une clé API. Vous pouvez en obtenir une en créant un compte sur le site d'OpenAI. Puis définissez la variable d'environnement OPENAI_API_KEY dans votre fichier .env :
NITRO_OPEN_AI_API_KEY=Enfin, créez une variable d'exécution dans la configuration Nitro :
export default defineNuxtConfig({
runtimeConfig: {
openAiApiKey: '',
},
// ...
})Nous sommes maintenant prêts à commencer à construire notre Agent IA.
Diffuser du texte
La première étape consiste à s'assurer que notre Agent IA peut générer du texte à partir de l'entrée utilisateur. Cela peut être plus difficile qu'il n'y paraît, mais l'AI SDK fournit un moyen simple d'y parvenir.
Créez un nouvel endpoint dans le serveur Nitro qui recevra la requête utilisateur et renverra la réponse générée par l'IA :
mkdir server/api
touch server/api/chat.tsEnsuite, créez l'endpoint dans server/api/chat.ts :
import { createOpenAI } from '@ai-sdk/openai'
import { convertToModelMessages, streamText } from 'ai'
import { defineEventHandler, defineLazyEventHandler, readBody } from 'h3'
import { useRuntimeConfig } from 'nitropack/runtime'
export default defineLazyEventHandler(() => {
const runtimeConfig = useRuntimeConfig()
const model = createOpenAI({
apiKey: runtimeConfig.openAiApiKey,
})
return defineEventHandler(async (event) => {
const { messages } = await readBody(event)
return streamText({
model: model('gpt-5-nano'),
system: `You are a helpful assistant.`,
messages: convertToModelMessages(messages),
}).toUIMessageStreamResponse()
})
})Il y a deux sections importantes dans ce fichier.
- Création du modèle OpenAI :
const model = createOpenAI({
apiKey: runtimeConfig.openAiApiKey,
})Cela crée l'adaptateur pour le modèle OpenAI. Si vous souhaitez utiliser un autre fournisseur, changez le code de création de l'adaptateur. C'est aussi ici que nous utilisons openAiApiKey depuis la configuration d'exécution.
- Diffuser des réponses textuelles :
return streamText({
model: model('gpt-5-nano'),
system: `You are a helpful assistant.`,
messages: convertToModelMessages(messages),
}).toUIMessageStreamResponse()La deuxième section importante est la diffusion des réponses textuelles. Nous utilisons la fonction streamText de l'AI SDK pour diffuser les réponses générées par l'IA au client. Nous lui donnons le modèle, un prompt système, et les messages de l'utilisateur. La fonction toUIMessageStreamResponse transforme la réponse dans un format adapté à la construction du frontend. Si vous voulez uniquement le texte, vous pouvez utiliser toTextStreamResponse.
Tous ces composants sont encapsulés dans un gestionnaire d'événements "lazy" pour garantir que le modèle n'est créé qu'une seule fois, lors de la première requête. Cela évite que chaque requête ne crée une nouvelle instance du modèle.
Vous pouvez tester l'endpoint de votre Agent IA avec la commande curl suivante :
curl -X POST http://localhost:3000/api/chat \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "user",
"parts": [
{
"type": "text",
"text": "Why is the sky blue?"
}
]
}
]
}'Cette commande envoie un message utilisateur d'exemple à votre endpoint /api/chat et diffuse la réponse générée par l'IA.
N'est-ce pas beau dans sa simplicité ?
Appeler un outil
Maintenant, nous pouvons ajouter un outil à notre Agent IA. Pour rappel, les outils sont des fonctions que l'Agent IA peut appeler pour effectuer des tâches spécifiques ; le code s'exécute côté serveur, pas chez le fournisseur d'IA.
Pour cet exemple, nous allons ajouter un simple outil d'addition. Avant d'aller plus loin, installez Zod pour créer des schémas :
pnpm add zodAjoutez maintenant l'outil addition à notre Agent IA :
return streamText({
model: model('gpt-5-nano'),
system: `You are a helpful assistant.`,
tools: {
addition: tool({
description: 'Adds two numbers',
inputSchema: z.object({
a: z.number().describe('The first number'),
b: z.number().describe('The second number'),
}),
execute: ({ a, b }) => ({
a,
b,
result: a + b
}),
}),
},
messages: convertToModelMessages(messages),
}).toUIMessageStreamResponse()Enfin, mettez à jour notre prompt pour s'assurer que l'IA utilisera le nouvel outil :
return streamText({
model: model('gpt-5-nano'),
system: `You are a helpful assistant. You can use the tool to add two numbers together.`,
// ...
}).toUIMessageStreamResponse()Et essayons :
curl -X POST http://localhost:3000/api/chat \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "user",
"parts": [
{
"type": "text",
"text": "What is 2 + 2?"
}
]
}
]
}'Remarquez-vous quelque chose dans la réponse ?
L'IA effectue le calcul en utilisant l'outil d'addition :
data: {"type":"tool-output-available","toolCallId":"call_Zmi5NtcVDRFZsZHcsULlutnG","output":{"a":12,"b":24,"result":36}}Mais elle ne fournit pas la réponse finale directement. Elle ne dit pas "La réponse est 36." Si vous vous souvenez des trois capacités de l'IA, cela a du sens. L'IA a utilisé la capacité d'appel d'outils, donc elle ne peut pas fournir la réponse finale directement. Nous devons appeler de nouveau l'IA.
Nous devons en faire un Agent IA !
En faire un Agent
Grâce à l'AI SDK, il est trivial de créer un Agent IA. Nous devons simplement indiquer à streamText le nombre maximum d'étapes qu'il peut effectuer pour produire une réponse finale.
import { stepCountIs, streamText } from 'ai'
return streamText({
model: model('gpt-5-nano'),
system: `You are a helpful assistant. You can use the tool to add two numbers together.`,
stopWhen: stepCountIs(2),
// ...
}).toUIMessageStreamResponse()L'option stopWhen: stepCountIs(2) indique à l'AI SDK d'arrêter l'interaction lorsque l'IA a effectué deux étapes, ou lorsque la dernière étape est une réponse textuelle. Avec cela, notre Agent IA devrait effectuer l'appel d'outil puis générer une réponse basée sur la sortie de l'outil.
Note
Je recommande de lire la page Loop Control de la documentation pour comprendre ce qui se passe sous le capot.
Essayons :
curl -X POST http://localhost:3000/api/chat \
-H "Content-Type: application/json" \
-d '{
"messages": [
{
"role": "user",
"parts": [
{
"type": "text",
"text": "What is 2 + 2?"
}
]
}
]
}'Oui, ça marche ! Notre IA est désormais un Agent capable d'utiliser des outils et de générer des réponses à partir de leur sortie. Parfait !

Merci de me lire ! Je m'appelle Estéban, et j'adore écrire sur le développement web et le parcours humain qui l'entoure.
Je code depuis plusieurs années maintenant, et j'apprends encore de nouvelles choses chaque jour. J'aime partager mes connaissances avec les autres, car j'aurais aimé avoir accès à des ressources aussi claires et complètes lorsque j'ai commencé à apprendre la programmation.
Si vous avez des questions ou souhaitez discuter, n'hésitez pas à commenter ci-dessous ou à me contacter sur Bluesky, X, et LinkedIn.
J'espère que vous avez apprécié cet article et appris quelque chose de nouveau. N'hésitez pas à le partager avec vos amis ou sur les réseaux sociaux, et laissez un commentaire ou une réaction ci-dessous, cela me ferait très plaisir ! Si vous souhaitez soutenir mon travail, vous pouvez me sponsoriser sur GitHub !
Discussions
Ajouter un commentaire
Vous devez être connecté pour accéder à cette fonctionnalité.