De l'idée à la victoire : Hackathon Mistral AI Paris 2026
Tout a commencé par un tweet. Les choses commencent souvent par un tweet.
Le 10 février 2026, Mistral AI a annoncé un hackathon mondial. Je savais que les places étaient limitées, alors j'ai postulé immédiatement, en espérant être sélectionné, mais sans la moindre idée de ce que j'allais faire, et sans vraiment savoir dans quoi je m'embarquais. Juste l'envie de me laisser surprendre par l'aventure.
Pour le défi
J'ai déjà fait quelques hackathons, comme la Nuit de l'Info ou des hackathons plus entrepreneuriaux, mais le dernier remonte à des années. J'ai appris énormément grâce à ces expériences, et je suis sûr qu'elles m'ont fait progresser techniquement. Le premier hackathon que j'ai fait m'a ouvert les yeux sur le développement web, et je n'en suis jamais reparti.
Aujourd'hui, je connais évidemment beaucoup plus de choses en programmation, mais aussi plus de technos, plus de choses sur l'architecture d'un projet, et plus de méthodes pour découper le travail afin d'avoir quelque chose qui fonctionne en peu de temps.
Dans un hackathon, ces compétences sont décisives : un mauvais choix de tech ou un mauvais découpage peut ruiner toutes tes chances d'avoir un projet qui marche à la fin. Avoir un prototype fonctionnel (ou proof-of-concept) est obligatoire. L'idée et la façon dont elle est présentée comptent, bien sûr, mais sans prototype, tu ne peux même pas passer devant un jury.
Je vois donc vraiment ce hackathon comme une super opportunité de me challenger sur ces compétences. Est-ce que tout ce que j'ai appris ces dernières années aide vraiment ? Est-ce que je suis maintenant capable de livrer plus qu'une app CRUD dans un hackathon ?
En parallèle, l'IA a complètement changé la donne. Avant, les gens qui savaient à peine coder n'avaient pas beaucoup de chances de gagner un hackathon. Maintenant, tout le monde peut construire quelque chose avec l'IA. Jouer avec du code devient une commodité. Mais ça veut aussi dire que ceux qui savent coder peuvent produire des projets bien plus complexes et intéressants. Donc l'IA a clairement relevé la barre.
Qu'on soit clairs : le software engineering n'est pas mort. À un moment, sans une architecture correcte, une compréhension claire du code et de la façon de résoudre les problèmes, et savoir quel outil utiliser (et quand), tu ne termines pas le hackathon. Sans garde-fous, l'IA n'est qu'un générateur de dette.
Le dimanche avant le hackathon, j'ai reçu un email de Mistral AI avec pour sujet « Registration approved ». J'étais dedans ! Toujours aucune idée et aucune équipe, mais super heureux de faire partie de l'aventure, surtout avec une boîte comme Mistral AI.
L'aventure commence
La première étape, c'était de trouver une équipe. Le hackathon a démarré le 28 février 2026. J'ai reçu l'email d'acceptation le 22 février, donc j'avais une semaine pour y arriver.
Mistral a ouvert un canal dédié sur leur serveur Discord pour que les participants puissent se présenter et trouver des coéquipiers. Ça m'a pris quelques jours, mais j'ai fini par me présenter sur Discord. J'étais le premier dans le canal. Surprise : seules trois personnes (moi compris) se sont présentées.
Un autre canal était dédié à la recherche de coéquipiers. J'ai vu un message de quelqu'un nommé « Godefroy » qui disait qu'ils étaient deux doctorants en physique et qu'ils cherchaient quelqu'un avec des compétences frontend et une expérience produit. Il a aussi dit qu'ils pratiquaient le vibe coding. J'ai répondu immédiatement : j'étais partant pour les rejoindre.
Ils se connaissaient déjà, donc travailler avec eux serait plus simple. Et apporter un bon bagage en software engineering à l'équipe me semblait être un complément parfait à leurs compétences, leur façon de bosser en vibe-coding, et leur détermination à produire le meilleur projet possible. Le vibe coding dans la bonne direction, avec les bons outils au bon moment, peut rendre des vibe coders incroyablement productifs.
Quelques heures plus tard, il m'a envoyé un message sur Discord pour m'expliquer leur idée de projet.
Ensuite, on a planifié un appel le vendredi pour discuter de toutes les idées qu'on avait en tête et choisir celle sur laquelle on voulait travailler. Nous (eux) avions quelques idées. On a terminé l'appel avec une short list, et on a décidé de dormir dessus et de faire le choix final avant d'arriver au hackathon. À ce moment-là, on était quatre dans l'équipe.
Pour la victoire
Jusqu'à ce qu'on entende le nom de notre projet annoncé comme gagnant du hackathon, notre seul objectif était de s'amuser et d'apprendre.
Avant d'arriver au hackathon, on a eu une dernière discussion sur WhatsApp à propos de l'idée qu'on voulait faire. On a choisi un système en temps réel pour débunker des émissions politiques à la TV. Bien plus compliqué que ça n'en a l'air, mais on parlera du projet plus tard.
Le hackathon a commencé à 9 h le 28 février 2026, dans les bureaux de Raise à Paris, près des Invalides. Le petit-déjeuner était servi, et on a eu l'occasion de rencontrer les autres participants (et notre équipe) pour la première fois. C'est là que j'ai rencontré Emma et Godefroy, les deux doctorants en physique.
La réunion d'introduction était à 10 h, donc on avait le temps de discuter et de faire connaissance. La vérité, c'est qu'on avait surtout envie d'ouvrir nos laptops et de commencer à hacker. C'était aussi le moment où le quatrième membre de l'équipe a décidé de rejoindre une autre team. On n'était plus que trois, mais ça n'a pas changé notre détermination à produire le meilleur projet possible.

Après une heure de présentations sur le hackathon, les challenges des sponsors, et le planning du week-end, on a enfin pu aller chercher un endroit pour travailler dans le bâtiment. C'était un peu chaotique : 100 participants et pas beaucoup de place. Mais on a trouvé une petite table dans un coin d'une salle. On a passé les 30 heures suivantes là-bas, à bosser sur notre projet. On était idéalement placés près de l'espace repas, donc on pouvait savoir quand la nourriture était servie et être les premiers dans la file. Pas besoin d'attendre : tu prends et tu continues de travailler.

Dans les premières heures, on a structuré le projet en définissant les frontières : ce qu'on voulait faire, comment on voulait le faire, et quand on considérerait le projet comme « fini ». On a aussi commencé à se répartir le travail en fonction de notre compréhension initiale du problème et de nos compétences respectives.
Ensuite, on a codé jusqu'à la fin de la journée. Les pauses étaient courtes et rares, on était vraiment concentrés pour que ça marche, et c'était plus dur que prévu. Vers 22 h, nos cerveaux commençaient à être fatigués et irrités. Godefroy et Emma ont décidé d'aller dormir, et c'était clairement une bonne idée. J'ai pris une longue pause et je suis allé à la cuisine manger de la pizza. Une pause bien méritée avant de reprendre.

J'ai continué à bosser sur le projet de 23 h à 1 h 30. J'ai beaucoup refactoré du code, en essayant de le simplifier et de le rendre plus robuste, en espérant que ça marcherait pour le lendemain. Je suis finalement rentré vers 2 h, juste à temps pour attraper le dernier métro. Je n'étais pas vraiment fatigué, porté par l'adrénaline du hackathon, donc j'ai continué à hacker jusqu'à 6 h. J'ai fait une sieste jusqu'à 8 h, puis je suis retourné au hackathon pour le deuxième (et dernier) jour.
On avait jusqu'à 15 h 30 pour finir le projet, enregistrer une vidéo pour le présenter, et préparer la présentation pour le jury. Honnêtement, c'était énorme comme charge de travail, parce qu'on n'arrivait pas à faire fonctionner tous les composants ensemble. Chaque partie marchait bien seule, mais une fois assemblées, ça ne marchait plus du tout.
Pas le choix : il fallait que ça marche. Les choses ont commencé à fonctionner vers 14 h 30. On a filmé la vidéo à 15 h 22, on l'a uploadée à 15 h 28, et on a soumis le projet à 15 h 29. Oui, une minute avant la deadline. Comme d'habitude dans un hackathon.
On était très stressés, mais on y est arrivés, et on était vraiment fiers d'avoir quelque chose qui fonctionne à la fin du hackathon. On l'a fait marcher ! Merci Godefroy d'avoir trouvé la solution finale, et merci Emma d'avoir préparé à la fois la soumission et la présentation.
Tu crois que c'était la fin de l'aventure ? Non ! On avait une présentation, inachevée, et le texte n'était pas prêt. On avait seulement 3 minutes pour pitcher notre projet devant un jury d'experts, et on devait le faire en anglais. Donc, jusqu'à notre passage à 16 h 30, on a peaufiné les slides et préparé la démo live. Tout est allé si vite qu'on n'a même pas eu le temps d'être nerveux ou stressés. Ah, et la démo live a marché comme un charme. Aucun problème !

Trois minutes, c'est court, et on avait beaucoup à dire, mais ce sont les règles. Choisir les bons mots pour convaincre le jury que notre projet méritait de gagner. Un énorme merci à Roland d'avoir été notre timekeeper, et d'avoir été gentil et rassurant juste avant le pitch.

Merci Sam pour les photos, et pour la longue discussion du samedi après-midi !
Une fois que toutes les équipes ont présenté, tous les participants sont allés dans une salle pour attendre les résultats. Ils ont annoncé 12 finalistes qui devaient refaire une présentation finale devant le jury et tous les participants. Ils ont annoncé le premier nom, puis le deuxième. C'était nous ! Wow, vraiment ? On était finalistes ? Inattendu, et peut-être, juste peut-être, qu'on avait une chance de gagner ce hackathon ?
On a repitché devant tout le monde du mieux qu'on pouvait, et encore une fois, on a attendu les résultats. Cette fois, on n'a pas fait la démo live : on a juste présenté la vidéo.
Cinq minutes plus tard, le jury a annoncé le gagnant. Ils ont commencé par annoncer la troisième place, puis la deuxième, et enfin le vainqueur. On a entendu le nom de notre projet, et on n'y croyait pas. On s'est regardés, pour être sûrs qu'on avait entendu la même chose, et ouais : c'était bien notre équipe.
On a gagné le Hackathon Mistral AI Paris 2026 ! Irréel et inattendu ! On l'a fait ! 🫶

La semaine prochaine, on part pour la finale internationale ! On aura l'opportunité de présenter notre projet en live, devant des participants de tous les hackathons, pour tenter de gagner le prix mondial.
Une aventure incroyable qui a commencé par un tweet, et qui s'est terminée par une victoire. Très fier de l'équipe, du projet qu'on a construit, et de la façon dont on a travaillé ensemble. J'adore les hackathons !

Maintenant, il est temps de se reposer un peu et de préparer la suite.
Veristral
J'ai beaucoup parlé du hackathon, de l'ambiance, du planning, et de comment on a réussi à le faire marcher, mais je n'ai pas dit un mot du projet qu'on a construit (et qui a gagné le hackathon). Alors voilà.
L'idée
Notre idée était de construire un système en temps réel pour débunker des émissions politiques à la TV. On voulait pouvoir afficher, pendant l'émission, pendant que le présentateur parle, si ce qu'il dit est vrai ou non, s'il esquive la question, et s'il se contredit. Automatiquement, un pop-up apparaîtrait à l'écran pour apporter des informations supplémentaires aux spectateurs, les aider à mieux comprendre l'émission, et leur permettre de se faire leur propre avis sur ce qu'ils regardent.
Les fake news peuvent être vraiment dangereuses, et elles se propagent très vite, bien plus vite que la vérité. Parfois, des journalistes les débunkent plus tard, même des jours après l'émission. Malheureusement, c'est trop tard. Les dégâts sont faits, et le débunking ne touchera pas la même audience que la fake news. Les fake news sont une vraie menace pour la démocratie, et elles font partie des moyens qu'ont des puissances extérieures pour déstabiliser un pays.
Le vrai défi, c'était la contrainte temps réel. Comment, en quelques millisecondes, analyser la parole du présentateur, la comprendre, décider si c'est vrai ou non, l'enrichir avec des informations supplémentaires, et l'afficher à l'écran ? Honnêtement, c'est impossible. Pour l'instant, on n'a pas la technologie pour le faire de bout en bout.
Voxtral, le modèle speech-to-text (STT) temps réel de Mistral AI, a été annoncé comme étant sous les 200 ms, ce qui est impressionnant, mais ensuite il faut quand même analyser le texte, chercher des informations, et les renvoyer à l'écran. On a vite tapé dans le mur de la latence.
Il y a un autre problème. Le présentateur peut dire quelque chose puis se corriger quelques secondes plus tard. Si on affiche des informations dès qu'on les a, on peut se retrouver avec une expérience utilisateur catastrophique, et décrédibiliser complètement le système.
Donc il fallait trouver une autre solution pour avoir un système en temps réel.
Le buffer à la rescousse
La plupart des émissions de TV en direct ne sont pas vraiment en direct. Elles sont décalées de quelques secondes, et elles ont un buffer de retard pour pouvoir couper le flux si quelque chose d'inattendu se produit. Ce délai peut être bien plus important. Une émission française problématique a été forcée d'avoir un buffer de 45 minutes pour éditer le live en temps réel et retirer du contenu problématique avant la diffusion.
Ça nous apprend deux choses :
- Le concept de buffer entre le live et la diffusion existe déjà dans les émissions de TV.
- Le buffer peut être très long.
On peut utiliser ce buffer pour notre système temps réel. Imagine la situation suivante. À t0, le présentateur parle de quelque chose. Le flux est décalé de 30 secondes, donc les spectateurs regardent en réalité ce que le présentateur a dit à t-30 s. Pendant ces 30 secondes, on peut analyser la parole, la comprendre, décider si c'est vrai ou non, l'enrichir avec des informations supplémentaires, et renvoyer le tout à l'écran. À t+30 s, les spectateurs verront l'information à l'écran au même moment où ils entendent le présentateur en parler. De cette façon, on peut avoir un système en temps réel sans être limités par la technologie.
Du point de vue workflow, on a l'architecture simplifiée suivante :
Cette solution de buffer nous donne une large fenêtre pour analyser la parole du présentateur et planifier l'affichage de l'information au bon moment. On peut même utiliser les phrases suivantes pour améliorer le contexte et annuler un fact-check si le présentateur se corrige. C'est vraiment puissant et élégant.
Tu as peut-être déjà entendu parler de systèmes IA pour analyser et débunker des émissions TV, mais c'était toujours de l'analyse après coup. Notre système change la donne en pouvant le faire en temps réel et en touchant la même audience que la fake news. C'est un vrai game-changer dans la lutte contre les fake news. Si tu es un provider IA ou une entreprise média, et que ce projet t'intéresse, contacte-nous.
Construire le système
Construire un tel système en 30 heures, c'est un défi. Sans démonstration, on ne peut pas passer devant le jury, donc il fallait que ça marche à tout prix.
L'entrée du système, c'est le flux live de l'émission TV, plus précisément son audio. Cet audio est envoyé à un modèle de speech-to-text pour être transcrit en texte. Ensuite, un pipeline d'analyse (un peu) complexe se met en route pour analyser le texte, le comprendre, le fact-checker, et l'enrichir avec des informations supplémentaires. Enfin, l'information est envoyée à l'overlay pour être affichée à l'écran au bon moment.
Entre l'entrée et la sortie, on a utilisé deux instances d'OBS pour simuler un environnement de diffusion live. La première capturait le flux live (une seule caméra et un micro dans notre cas) avec un délai de 30 secondes pour simuler le buffer. La seconde capturait la sortie de la première OBS et ajoutait l'overlay pour obtenir un design propre et sympa. C'est cette seconde OBS qui est contrôlée par le système pour afficher l'information à l'écran au bon moment.
On a vraiment galéré à trouver une façon de simuler un live avec un buffer. Sur macOS, lancer OBS deux fois ne marche pas. Utiliser open -n -a OBS.app pour démarrer une seconde instance marche, mais la seconde instance était vraiment buggée. Pour les faire communiquer, j'ai essayé MediaMTX, même FFMpeg, avec tous les formats de broadcast possibles, mais OBS rappelait le flux de la première OBS sans aucun délai. OBS était trop smart pour nous. Au final, on a trouvé un contournement : streamer sur Internet depuis un premier ordinateur avec 30 secondes de délai et capturer ce stream sur un autre ordinateur. On avait un peu plus de 30 secondes de délai à cause du réseau et du temps de traitement, donc on a dû ajuster notre système de scheduling.
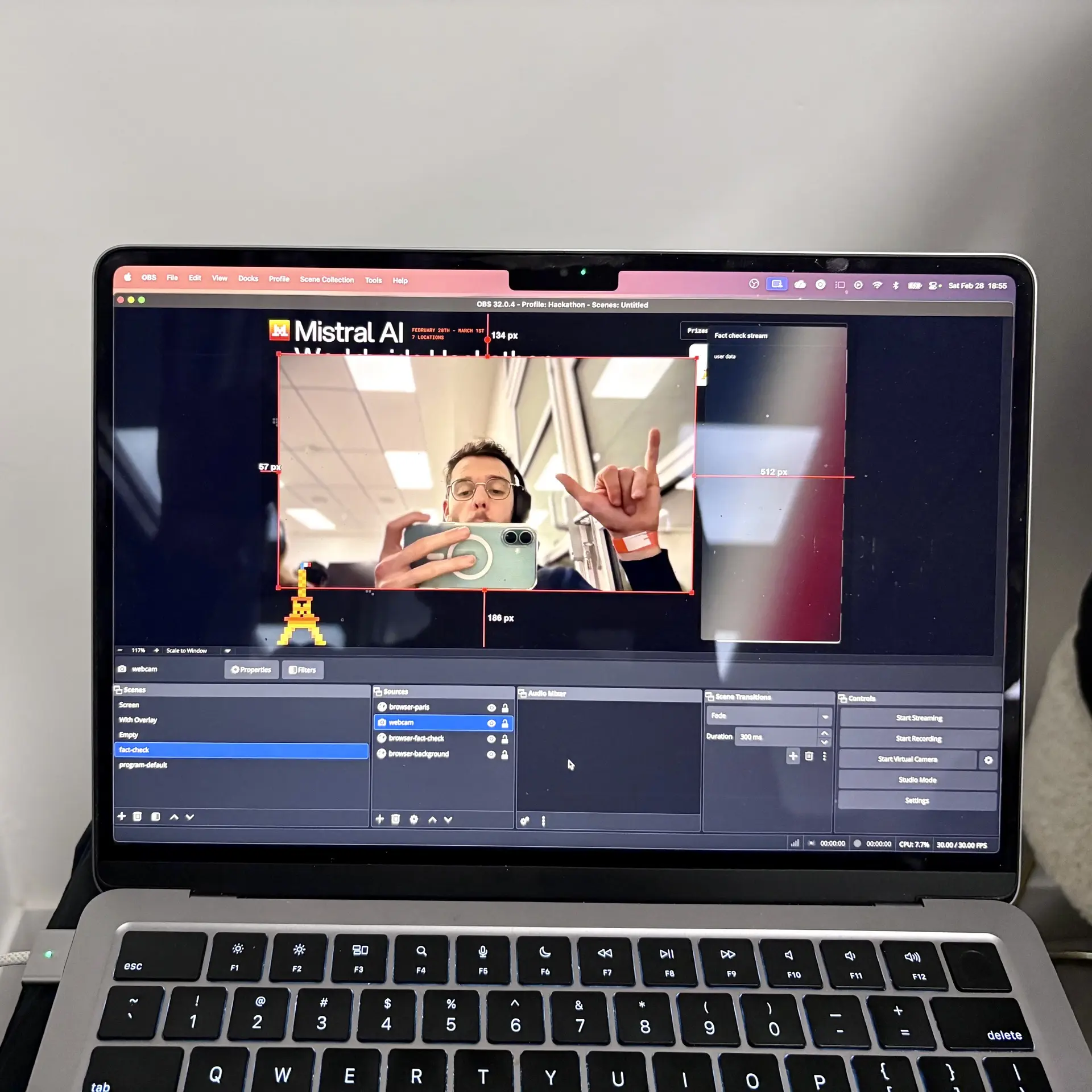
Ça ressemble à un setup instable, mais ça a marché !
La suite va devenir technique, n'hésite pas à sauter cette partie si les détails techniques ne t'intéressent pas.
Pour le speech-to-text, on a utilisé des modèles Mistral AI, en particulier Voxtral Realtime, sorti quelques semaines avant le hackathon. On attendait d'avoir une phrase complète avant de démarrer l'analyse. Cette partie pourrait être beaucoup améliorée : on pourrait avoir un système plus intelligent, et garder plus d'une phrase pour plus de contexte.
Pour le hackathon, on a juste ajouté une étape pour nettoyer le texte, parce que le speech-to-text peut faire des erreurs. Plus tu réduis le délai, moins la transcription est précise.
Pour le pipeline d'analyse, on a utilisé une combinaison de différents modèles Mistral AI assemblés de façon à former un workflow.
Tout commence avec un router agent qui reçoit des phrases. Ce router les analyse et détermine quels agents appeler ensuite via une sortie structurée. Ça nous permet d'avoir un workflow dynamique qui s'adapte au contenu de chaque phrase.
Les agents suivants sont ceux qui peuvent être exécutés après le router :
- Stats Agent : cet agent est appelé si la phrase contient des nombres, comme un budget, un pourcentage, ou une quantification. Il va essayer de vérifier si les chiffres sont corrects et de trouver leur source.
- Rhetoric Agent : cet agent est appelé si la phrase contient une question. Il analyse si le présentateur essaie d'esquiver la question, et si oui, il essaie de retrouver la question esquivée et d'en trouver la réponse.
- Personal Coherence Agent : cet agent est appelé si la phrase contient une déclaration qu'on peut vérifier en regardant les déclarations précédentes du présentateur. Il analyse si le présentateur est cohérent avec lui-même, ou s'il se contredit.
- Context Agent : cet agent est appelé si la phrase contient une déclaration à propos d'un événement, d'une loi, ou de toute information contextuelle qu'on peut vérifier. Il va chercher des informations pertinentes sur cette déclaration, et vérifier si c'est correct ou non.
Les Stats Agent et Context Agent avaient tous les deux accès à Internet via un outil de recherche web, afin de trouver des informations pertinentes pour vérifier les affirmations du présentateur.
Ensuite, les sorties de tous ces agents (selon lesquels sont appelés) sont agrégées dans un Editor Agent. Cet agent écrit un texte lisible et compréhensible pour les spectateurs. Sa sortie est aussi structurée, et c'est ce qu'on rendait dans OBS via l'overlay web.
Honnêtement, c'est un pipeline très simple. Ça a bien marché pour le hackathon, mais dans un produit réel, il devrait être beaucoup plus complexe, avec plus d'agents et plus de fonctionnalités. Par exemple, on a exploré un système où le workflow attend un signal avant de se mettre en sommeil. Ce signal serait envoyé par le STT un peu après la phrase initiale pour apporter plus de contexte, et déterminer si le présentateur se corrige ou non.
Ça fait partie d'un workflow Temporal. Une fois terminé, on demande à Temporal de dormir jusqu'au bon moment pour afficher l'information à l'écran. On connaît ce moment parce qu'on connaît t0 (l'instant juste avant que le STT renvoie une phrase) et la taille du buffer. Par exemple, si t0 vaut 14:15:13, on sait que le workflow doit dormir jusqu'à 14:15:43. Peu importe combien de temps prend l'analyse, l'information sera affichée au bon moment.
Avant de dormir, on vérifie si l'heure actuelle est toujours avant l'heure planifiée. Sinon, on jette l'information car il est trop tard pour l'afficher. Quand le workflow se réveille, il envoie l'information à une autre application dédiée.
Temporal nous permet de paralléliser l'analyse sans complexité, et de planifier l'affichage des informations au bon moment sans passer par une base de données et un scheduler custom. On aurait pu faire ça avec le task scheduling de Laravel, mais Emma et Godefroy étaient plus à l'aise avec Python. Un autre avantage de Temporal (et de l'approche « trigger un workflow ») est qu'on découple complètement l'analyse du scheduling.
L'interface entre Godefroy, qui bossait sur le STT, et Emma, qui bossait sur l'analyse, c'était Temporal : un système robuste et bien documenté. Pas besoin de réinventer la roue, et c'est super important dans un hackathon pour gagner du temps et éviter les bugs bloquants.
Pour contrôler la seconde OBS, j'ai construit une application Laravel. Cette application a un endpoint qui reçoit l'information à afficher depuis le workflow Temporal. Ensuite, elle envoie les nouvelles données au frontend avec Reverb (le système WebSocket de Laravel). Enfin, l'endpoint déclenche un changement de scène dans la seconde OBS pour afficher l'information à l'écran.
Tu peux avoir du mal à comprendre cette partie. OBS est un logiciel de live streaming. Tu as des scènes dans lesquelles tu peux empiler différentes sources, comme une caméra, une capture d'écran, ou une source navigateur. Cette dernière est très intéressante parce qu'elle permet d'utiliser une page web comme source dans OBS.
Donc, l'application que j'ai construite contient à la fois le backend (pour recevoir l'information et l'envoyer au frontend) et un frontend qui écoute le WebSocket et met à jour le contenu de la page web. Ce frontend est intégré dans la seconde OBS comme une source navigateur avec un fond transparent, ce qui permet toujours de voir le présentateur derrière. On avait deux scènes dans la seconde OBS : une avec une grande source caméra pour montrer le présentateur quand il n'y avait rien à afficher, et une avec une plus petite caméra pour faire de la place à l'information à l'écran.
Avec un peu plus de recul, le système complet ressemble à ça :
Tout notre code source est disponible sur GitHub : Barbapapazes/hackathon-paris
Petite note sur Temporal
Temporal peut sembler overkill, mais ça a sauvé notre projet. Prends un moment pour trouver une solution à notre problème de parallélisation et de scheduling sans Temporal, et tu réaliseras vite à quel point c'est compliqué de construire un système de scheduling robuste qui scale. Avec Temporal, ça marche, tout simplement.
On l'a utilisé pour deux raisons :
- Temporal a organisé un meetup à Paris le 5 novembre 2025, et j'y ai assisté. Un des talks était « Combining Temporal's durability with streaming of LLM responses using NATS Jetstream » par Nicolas Moreau, software engineer chez Mistral AI.
- Le scheduling, ou le fait d'attendre un moment précis pour faire quelque chose, c'est vraiment un sujet de workflow. Temporal est un moteur de workflow.
Ces deux points ont suffi à me convaincre d'utiliser Temporal. Si on utilise la même technologie que Mistral AI, peut-être que ça rendra le projet plus facile à comprendre et plus intéressant et réaliste pour le jury. Je ne sais pas comment ça a influencé la perception du jury, mais on en a parlé avec des ingénieurs Mistral AI qui étaient présents.
Au travail, on utilise Temporal dans notre infrastructure backend. C'est tellement puissant que j'essaie de tout mettre dans Temporal.
Pour mes projets perso, j'utilise surtout Cloudflare Workflows. Sous le capot, c'est très différent, mais d'un point de vue usage, ça donne la même sensation. Une fois que tu as la puissance d'un workflow, tout dans ta vie devient un workflow. Le truc drôle, c'est que j'automatise ma vie en ce moment, principalement avec Cloudflare Workflows, donc les utiliser pendant le hackathon était naturel pour moi.
Passer au monde réel
Faire confiance au système dès le début peut être très difficile, donc on peut facilement imaginer un setup où le système fait la majeure partie du travail, avec un humain dans la boucle pour valider, vérifier, et corriger l'information avant qu'elle soit affichée à l'écran. C'est une solution faisable comme première étape.
Mais un système complètement autonome est le vrai objectif, parce que retirer l'humain de la boucle, surtout dans des émissions politiques, est vraiment important pour réduire les biais et s'assurer que tous les partis politiques sont traités de la même manière.
Maintenant que le hackathon est terminé, il y a tellement de choses qu'on peut faire pour continuer d'améliorer le projet, et j'ai entendu de sources fiables que Mistral AI était intéressé, et peut-être même en train de construire un système similaire.
On est allés un peu plus loin pendant le hackathon, mais on n'a pas réussi à le faire marcher. On a commencé à construire un système qui collecte tout ce qu'on fact-check pendant l'émission live et le rend disponible sur un site centralisé. Comme ça, les spectateurs pourraient juste scanner un QR code à l'écran pour accéder au fact-check complet, puisque l'espace est limité sur l'overlay.
À propos de l'usage intensif de l'IA
Pendant les deux jours du hackathon, on a énormément utilisé l'IA pour écrire du code.
Emma s'est principalement appuyée sur Gemini Pro via son chat UI pour écrire du code, tandis que Godefroy utilisait à la fois Gemini Pro via Antigravity et le chat, ainsi que Codex d'OpenAI. De mon côté, j'ai utilisé GitHub Copilot Pro via VS Code, et principalement Sonnet 4.6 et GPT-5.3-Codex.
Même avec son plan payant, Emma a atteint la limite de Gemini Pro, et elle a dû attendre quelques heures avant de pouvoir l'utiliser à nouveau. Godefroy a dû alterner entre Antigravity et Codex pour éviter d'atteindre la limite de l'un des deux. Avec GitHub Copilot Pro, il n'y a pas de hard limit car on paye par requête. Pour te donner une idée, j'ai fait 94 requêtes en un week-end. Le plan Pro inclut 300 requêtes par mois, donc j'ai brûlé à peu près un tiers du quota mensuel sur un week-end.
C'est intéressant de voir comment on a chacun utilisé l'IA différemment. Emma utilisait un notebook Jupyter pour écrire l'algorithme de débunking. Elle alternait entre poser des questions à Gemini Pro via le chat et copier-coller le code dans le notebook. Godefroy utilisait Antigravity Agent ou Codex pour éditer et commit du code directement. C'était une façon de travailler très vibe-coding.
Pour tous les deux, j'ai été vraiment impressionné par la vitesse à laquelle ils généraient du code qui marche. Même pour configurer OBS, Godefroy a demandé à Gemini Pro comment faire, et en quelques minutes, il avait une configuration fonctionnelle.
Cependant, comme je l'ai dit au début de l'article, sans comprendre le code, une organisation claire, et un projet bien structuré, ça devient un bazar très vite. Et ensuite, restructurer le code pour le rendre plus propre, extensible, et robuste devient un cauchemar.
J'ai passé beaucoup de temps entre samedi et dimanche à refactorer à la fois l'algorithme de débunking et le code du workflow pour le rendre plus robuste pour les fonctionnalités à venir.
Avec l'IA, perdre le contrôle du code est très facile. Est-ce que c'est grave ? Je ne sais toujours pas.
Peut-être qu'on est en train de créer une abstraction de plus haut niveau au-dessus du code, où on ne se soucie pas des détails d'implémentation. Peut-être que c'est ok la plupart du temps. Peut-être que c'est la pire abstraction, et que le code comme commodité est une illusion pour les non-software engineers.
Une chose dont je suis sûr, en revanche : créer des applications complexes requiert toujours une bonne architecture, la capacité à découper des problèmes complexes en problèmes plus petits (adaptés aux capacités de l'IA, pas aux capacités humaines), et une bonne compréhension du code.

Merci de me lire ! Je m'appelle Estéban, et j'adore écrire sur le développement web et le parcours humain qui l'entoure.
Je code depuis plusieurs années maintenant, et j'apprends encore de nouvelles choses chaque jour. J'aime partager mes connaissances avec les autres, car j'aurais aimé avoir accès à des ressources aussi claires et complètes lorsque j'ai commencé à apprendre la programmation.
Si vous avez des questions ou souhaitez discuter, n'hésitez pas à commenter ci-dessous ou à me contacter sur Bluesky, X, et LinkedIn.
J'espère que vous avez apprécié cet article et appris quelque chose de nouveau. N'hésitez pas à le partager avec vos amis ou sur les réseaux sociaux, et laissez un commentaire ou une réaction ci-dessous, cela me ferait très plaisir ! Si vous souhaitez soutenir mon travail, vous pouvez me sponsoriser sur GitHub !
Discussions
Ajouter un commentaire
Vous devez être connecté pour accéder à cette fonctionnalité.