Créer une App Nuxt Full-Stack : une Aventure sur Twitch
Je l'ai enfin fait !
Après des mois à y penser, j'ai enfin lancé mon premier stream sur Twitch, le 28 avril 2024. C'est une étape très importante pour moi car j'adore partager mes connaissances et parler de ce que je fais.
Quand j'étais à l'école, j'organisais des cours pour expliquer la programmation à mes camarades. J'ai aussi rejoint une communauté pour expliquer les choses sur les ordinateurs, j'ai donné quelques conférences, et récemment, j'ai commencé à écrire des articles sur mon blog.
Twitch est juste une nouvelle façon de continuer à faire ce que j'aime !
Dans les semaines à venir, je partagerai avec vous mon parcours pour construire une application Full-Stack Nuxt, déployée sur Cloudflare, appelée Orion. J'expliquerai comment je l'ai construite, les choix que j'ai faits, et les problèmes que j'ai rencontrés. Mon objectif à travers cet article est de vous donner une vue honnête et réaliste des avantages et des inconvénients de la création d'une application Full-Stack en edge avec Nuxt en mai 2024, à travers le processus de construction d'une application réelle.
Dans cet article, je partagerai avec vous chaque étape de cette première série de streams. Si vous ne parlez pas français (car les streams sont en français), si vous avez manqué un stream, ou si vous préférez simplement lire, cet article est fait pour vous !
Découverte de NuxtHub et Début de l'Application Full-Stack Nuxt

Orion est une application Full-Stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir la rediffusion sur YouTube et le code source est open-source sur GitHub.
C'était mon premier stream, et pour être honnête, j'étais un peu stressé. Le moment où vous devez passer de la scène "Starting Soon" à la caméra est difficile. Mais une fois que j'ai commencé à parler, tout s'est bien passé. Cependant, cela ne veut pas dire que c'est le meilleur stream que vous verrez jamais. Nous allons nous améliorer !
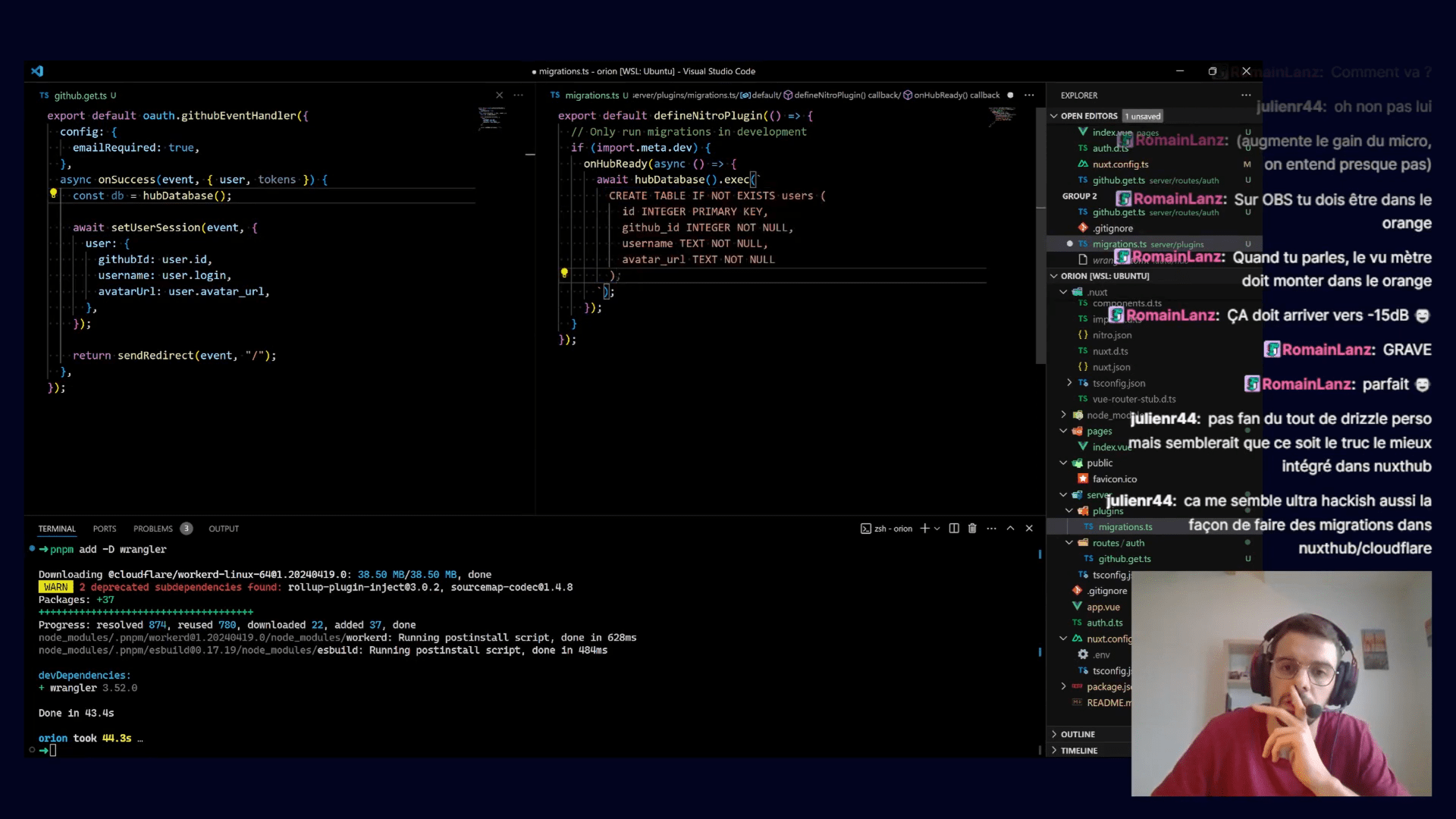
Tout d'abord, je présente NuxtHub. C'est une plateforme développée par l'équipe Nuxt pour faciliter le déploiement et la gestion des applications Nuxt déployées sur Cloudflare. En quelques clics, vous pouvez déployer votre application Nuxt sur Cloudflare. C'est vraiment magique ! Grâce à un module Nuxt, vous pourrez développer votre application localement et ensuite la déployer sans modifier votre code. Tout, de la base de données au stockage du blog, fonctionne parfaitement dans les deux environnements.
J'ai essayé de déployer un modèle depuis NuxtHub pour montrer à quel point il est facile d'utiliser la plateforme. J'ai choisi le modèle Atinotes. Malheureusement, cette application produit un bundle de plus de 1 Mo, la limite pour le niveau gratuit, donc le déploiement échoue. Dommage pour une démonstration. Après cet échec, j'ai pensé à un moyen de prévenir cela et d'informer les utilisateurs si un modèle nécessite un plan payant ou non. J'ai soulevé un problème qui a été rapidement corrigé !. La démo attendra plus tard.
Après cet effet de démonstration, nous avons commencé à coder l'application Full-Stack Nuxt en ajoutant l'authentification. Pour ce faire, nous utilisons le module nuxt-auth-utils de Sébastien Chopin. Avec quelques lignes de code, nous ajoutons l'authentification. Voici le code que nous avons utilisé :
export default oauth.githubEventHandler({
config: {
emailRequired: true,
},
async onSuccess(event, { user, tokens }) {
await setUserSession(event, {
user: {
githubId: user.githubId,
},
})
return sendRedirect(event, '/')
},
})C'est vraiment simple et ça fonctionne à merveille, bien intégré dans une application Nuxt.
Pour terminer le stream, j'ai rapidement configuré NuxtHub dans mon application pour montrer à quel point il est facile de jouer avec une base de données. J'ai essayé d'utiliser SQL brut, mais la recette pour migrer la base de données ne fonctionnait pas. J'ai soulevé un problème à ce sujet et il est maintenant corrigé ! Après ce deuxième échec, j'ai décidé de commencer à utiliser Drizzle ORM, un ORM simple mais puissant compatible avec les workers de Cloudflare. Dans tous les cas, j'aurais dû utiliser Drizzle car gérer tout avec SQL brut est trop de travail.
Pendant le live, quelqu'un a demandé comment appliquer les migrations à la base de données de production. Je dois admettre que je ne connaissais pas la réponse et rien dans la documentation n'était clair à ce sujet. J'ai soulevé un problème à ce sujet, qui a reçu une réponse. Il faut déployer votre application puis démarrer le développement local avec une connexion distante pour exécuter les migrations Clairement, c'est loin d'être idéal pour le moment, mais avec les prochaines tâches Nitro, cela devrait être plus facile dans un avenir proche. Je l'espère vraiment.
Globalement, je suis tellement heureux d'avoir commencé ce stream. Même si ce n'est pas encore parfait, commencer est déjà un grand pas en avant, et je sais que les futurs streams ne feront que devenir plus faciles à commencer.
J'étais tellement stressé que je suis allé très vite dans mes explications, donc j'ai décidé que le prochain stream serait plus bavard pour réexpliquer différents concepts.
Le projet est open-source et disponible sur GitHub à orion ! Donnez-lui une étoile si vous l'aimez ! ⭐
Discussion sur Cloudflare, NuxtHub et GitHub OAuth

Orion est une application Full-Stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir la rediffusion sur YouTube et le code source est open-source sur GitHub.
J'étais frustré par mon premier live stream. Avec le stress, je n'ai pas expliqué des concepts comme ce qu'est Cloudflare, ce qu'est l'edge et comment NuxtHub est lié à Cloudflare. Mais je sais qu'il est important d'expliquer ces concepts puisque ce sont des technologies nouvelles et que tout le monde ne les connaît pas.
À StrasbourgJS ou Devoxx, j'ai parlé d'UnJS et des problèmes résolus par l'écosystème. Beaucoup de personnes, pendant ou après, m'ont demandé ce qu'est l'edge. Qu'est-ce que c'est ? Pourquoi en avons-nous besoin ? D'où cela vient-il ?
Le but de mes streams est de tester cette nouvelle technologie, et avec ces retours, il était nécessaire d'expliquer ces concepts.
Cloudflare en un coup d'œil
Cloudflare est une entreprise qui propose de nombreux services pour rendre le web plus rapide et plus sécurisé, comme une solution zéro-trust, un WAF, un CDN, un DNS, une protection contre les DDoS, et plus encore, pour les entreprises comme pour les particuliers.
Leur produit le plus connu est le proxy inverse. Cloudflare agit comme le point d'entrée principal et unique pour votre trafic. Ensuite, il dirigera, en interne, le trafic vers le bon serveur en utilisant le DNS. Cela permet de cacher votre IP serveur, de mettre en cache les ressources statiques et de protéger votre serveur contre les attaques DDoS.

Pour fournir ces services, ils ont construit un réseau de centres de données à travers le monde pour être le plus proche possible des utilisateurs afin de servir le contenu mis en cache plus rapidement et de pouvoir atténuer les attaques. Cela s'appelle le réseau edge. Il est à la frontière entre les utilisateurs et le web, pour lequel il constitue la passerelle.
En septembre 2017, ils ont annoncé Cloudflare Workers. Pour comprendre l'objectif à l'époque, citons l'article :
Que faire si vous souhaitez équilibrer la charge avec un algorithme d'affinité personnalisé ? Que faire si les règles de mise en cache HTTP standard ne sont pas tout à fait adaptées et que vous avez besoin de logique personnalisée pour améliorer votre taux de cache ? Que faire si vous voulez écrire des règles WAF personnalisées adaptées à votre application ?
Vous voulez écrire du code
Les Workers ont été lancés pour permettre aux développeurs de personnaliser l'infrastructure selon leurs besoins. La solution Cloudflare Workers est construite sur l'API Service Worker, une norme dans le navigateur pour intercepter et modifier les requêtes et les réponses.
Depuis lors, ils ont construit une plateforme complète pour les développeurs autour des workers :
- Workers KV, magasin de clés-valeurs sans serveur
- D1, base de données SQL sans serveur
- R2, stockage d'objets sans serveur
- Queues, files d'attente de tâches sans serveur
- Workers AI, inférence GPU sans serveur
Avec tous ces services, il est maintenant (théoriquement, et c'est le but de cette série de répondre à la question) possible de construire une application entièrement sur le réseau mondial de Cloudflare.
NuxtHub

Depuis la version 3 de Nuxt, l'équipe pousse l'edge. Nitro, la partie serveur de Nuxt, peut être déployée partout, sur les plateformes actuelles et futures, et est optimisée pour l'edge. H3, le serveur HTTP sous-jacent, se réveille en moins de 2 ms, et la sortie de build de Nitro est inférieure à 1 Mo, modules Node inclus.
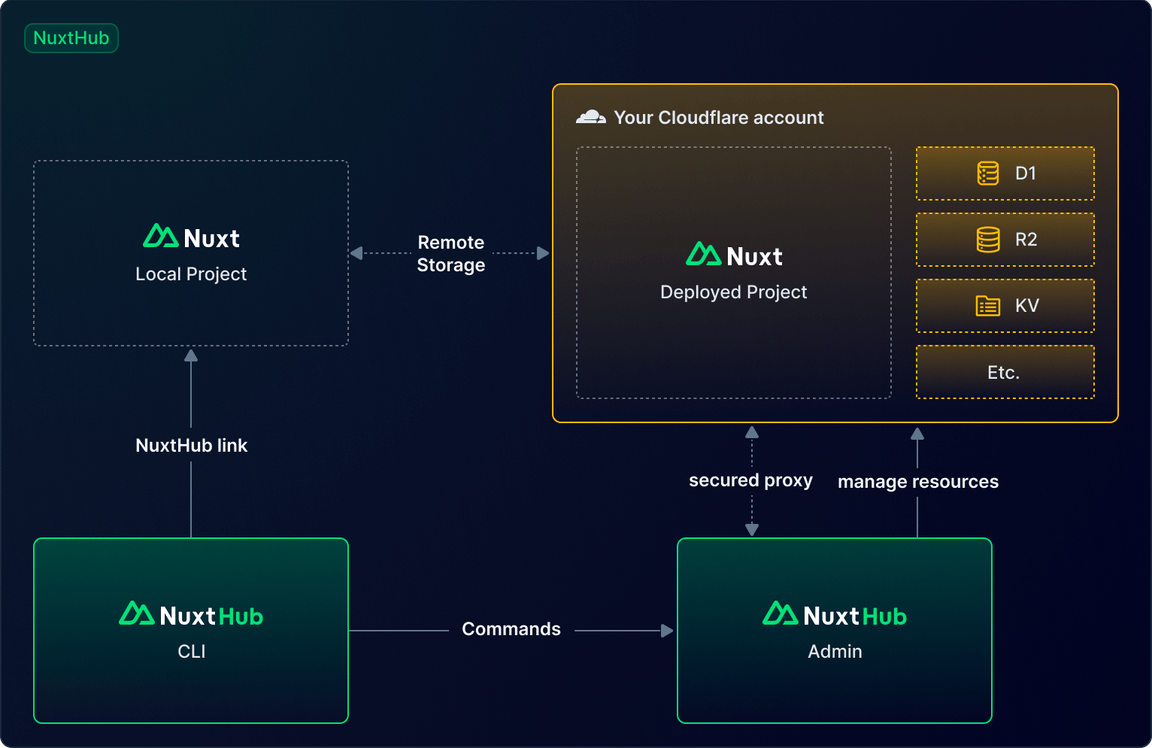
NuxtHub est la continuité de cet effort. D'abord, c'est une plateforme pour déployer des applications Nuxt sur Cloudflare. C'est un déploiement en deux clics. Vous connectez votre compte Cloudflare car c'est construit sur Cloudflare, vous choisissez un modèle ou un dépôt, vous cliquez sur déployer, et c'est tout. Votre application est en direct sur l'edge. On a l'impression que c'est de la magie.
NuxtHub est également un module pour votre application Nuxt afin d'ajouter des fonctionnalités d'accès aux données. Localement, vous pourrez jouer instantanément avec une base de données, un magasin KV, et même un stockage d'objets. En production, vous n'avez pas besoin de changer votre code, il fonctionnera de la même manière. C'est clairement la véritable magie de NuxtHub, alimentée par workerd.
Il y a aussi une fonctionnalité permettant à un environnement de développement local d'interagir avec les données distantes. Pas sûr du cas d'utilisation, mais c'est définitivement intéressant.
Même si la plateforme est encore nouvelle, annoncée lors de Vue Amsterdam 2024, elle est déjà très prometteuse. L'équipe est très réactive, et la plateforme évolue rapidement. Je suis très impatient de voir ce que l'avenir réserve à NuxtHub, mais il y a quelques indices dans la documentation :
Nous prévoyons de fournir une expérience backend complète pour les applications Nuxt à travers divers packages @nuxthub.
- @nuxthub/core : Package principal pour fournir des fonctionnalités de stockage
- @nuxthub/auth : Ajouter l'authentification pour la gestion des utilisateurs (bientôt)
- @nuxthub/email : Envoyer des e-mails transactionnels à vos utilisateurs (bientôt)
- @nuxthub/analytics : Comprendre votre trafic et suivre les événements au sein de votre application et API (bientôt)
- @nuxthub/... : Vous le nommez !
GitHub OAuth
Lors du précédent live stream, j'ai ajouté l'authentification, en utilisant nuxt-auth-utils à Orion, l'application Full-Stack Nuxt. J'ai utilisé GitHub OAuth, et je pense qu'il est important de voir comment cela fonctionne en coulisses.
Pendant le live, nous avons plongé dans le code, et j'ai expliqué comment cela fonctionne. Voici un schéma pour vous aider à comprendre le processus :
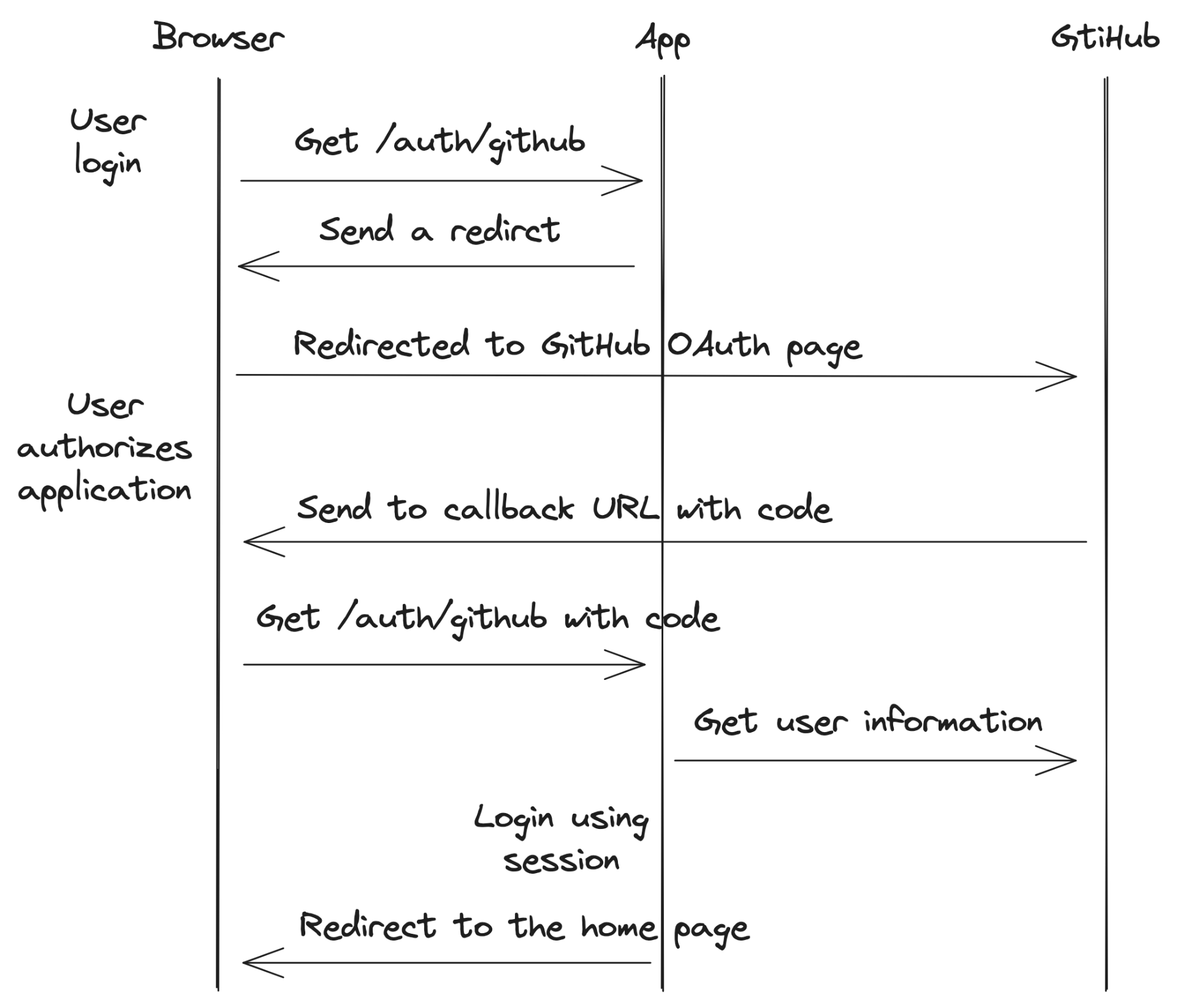
- L'utilisateur clique sur le bouton de connexion, qui pointe vers
/auth/github. - Le serveur envoie une redirection vers la page OAuth de GitHub.
- L'utilisateur accepte l'autorisation de GitHub.
- GitHub redirige l'utilisateur vers l'URL de rappel de l'application avec un code.
- Le serveur échange le code contre des tokens.
- Le serveur utilise les tokens pour obtenir les informations de l'utilisateur.
- Le serveur stocke l'utilisateur dans une session.
- Le serveur redirige l'utilisateur vers la page d'accueil.
Dans ces étapes, le serveur est Nitro, et nous ne parlons pas des erreurs possibles. Il y a de nombreuses erreurs possibles comme le refus de l'autorisation par l'utilisateur, un code invalide, des tokens invalides, l'utilisateur non trouvé, etc. Chaque erreur doit être gérée pour offrir une bonne expérience utilisateur.
Code du gestionnaire OAuth GitHub
Voyons maintenant le code de nuxt-auth-utils pour comprendre comment il fonctionne.
Pour simplifier, j'ai retiré certaines parties du code qui ne sont pas nécessaires à la compréhension du processus, et je me suis concentré sur les étapes principales. Vous pouvez trouver le code complet dans le dépôt GitHub.
/**
* Gestionnaire d'événements OAuth GitHub.
*
* _Le code est simplifié pour l'article et ne fonctionne pas tel quel._
*/
export function githubEventHandler({ config, onSuccess }: OAuthConfig<OAuthGitHubConfig>) {
return eventHandler(async (event: H3Event) => {
config = { /** ... */}
/**
* Récupérer la requête depuis l'événement.
*/
const query = getQuery(event)
if (query.error) {
// Gérer l'erreur
return
}
if (!query.code) {
/**
* Rediriger vers la page OAuth GitHub s'il n'y a pas de code dans la requête.
* Si l'utilisateur accepte l'autorisation, GitHub redirigera l'utilisateur vers l'application avec le code.
* Le code est un code unique à échanger contre les tokens.
*/
const redirectUrl = getRequestURL(event).href
return sendRedirect(
event,
withQuery(config.authorizationURL as string, {
client_id: config.clientId,
redirect_uri: redirectUrl,
scope: config.scope.join(' '),
...config.authorizationParams,
}),
)
}
/**
* Utiliser le code pour obtenir les tokens.
*/
const tokens: any = await $fetch(
config.tokenURL as string,
{
method: 'POST',
body: {
code: query.code,
},
},
)
const accessToken = tokens.access_token
/**
* Utiliser le token d'accès pour obtenir les informations de l'utilisateur.
*/
const user: any = await ofetch('https://api.github.com/user', {
headers: {
Authorization: `token ${accessToken}`,
},
})
/**
* Appeler le callback onSuccess avec l'utilisateur et les tokens.
*
* L'OAuth est terminé, et l'utilisateur peut maintenant être authentifié avec notre système.
* Avec Nitro, nous stockons l'utilisateur dans une session au sein d'un cookie.
*/
return onSuccess(event, {
user,
tokens,
})
})
}Comme on peut s'y attendre, le code est assez simple, et nous reconnaissons facilement les étapes que nous avons vues dans le schéma.
Conclusion
Je n'ai pas codé durant ce live. Je voulais expliquer de nombreux concepts importants pour aider chacun à comprendre le contexte du projet Orion. J'espère que c'était clair et que vous avez appris quelque chose de nouveau.
Le projet est open-source et disponible sur GitHub à orion ! Donnez-lui une étoile si vous l'aimez ! ⭐
Schéma SQL et Premiers Éléments de l'Interface Admin d'Orion

Orion est une application full-stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir le replay sur YouTube et le code source est open-source sur GitHub.
Dans ce troisième stream, j'ai créé le schéma SQL pour la base de données. J'ai ensuite configuré Nuxt UI et Nuxt UI Pro pour créer la mise en page de l'administration et le premier formulaire pour les catégories. Cet article est un résumé du stream et du travail réalisé.
Schéma SQL
Qu'est-ce qu'un schéma SQL et pourquoi ai-je créé ce schéma SQL ? Ce sont deux bonnes questions.
Un schéma SQL est un moyen d'organiser la base de données. C'est une feuille de route sur la manière dont la base de données sera structurée. Il est donc très utile de réfléchir à cela avant de commencer à coder. Il n'est pas nécessaire qu'il soit parfait, mais il aide à itérer sur la structure de la base de données, à éviter les erreurs et à avoir une vision claire du projet. Je pense personnellement que c'est un indispensable lorsqu'on commence un nouveau projet.
Avant d'écrire quoi que ce soit pour le projet Orion, j'ai donc créé le schéma SQL.
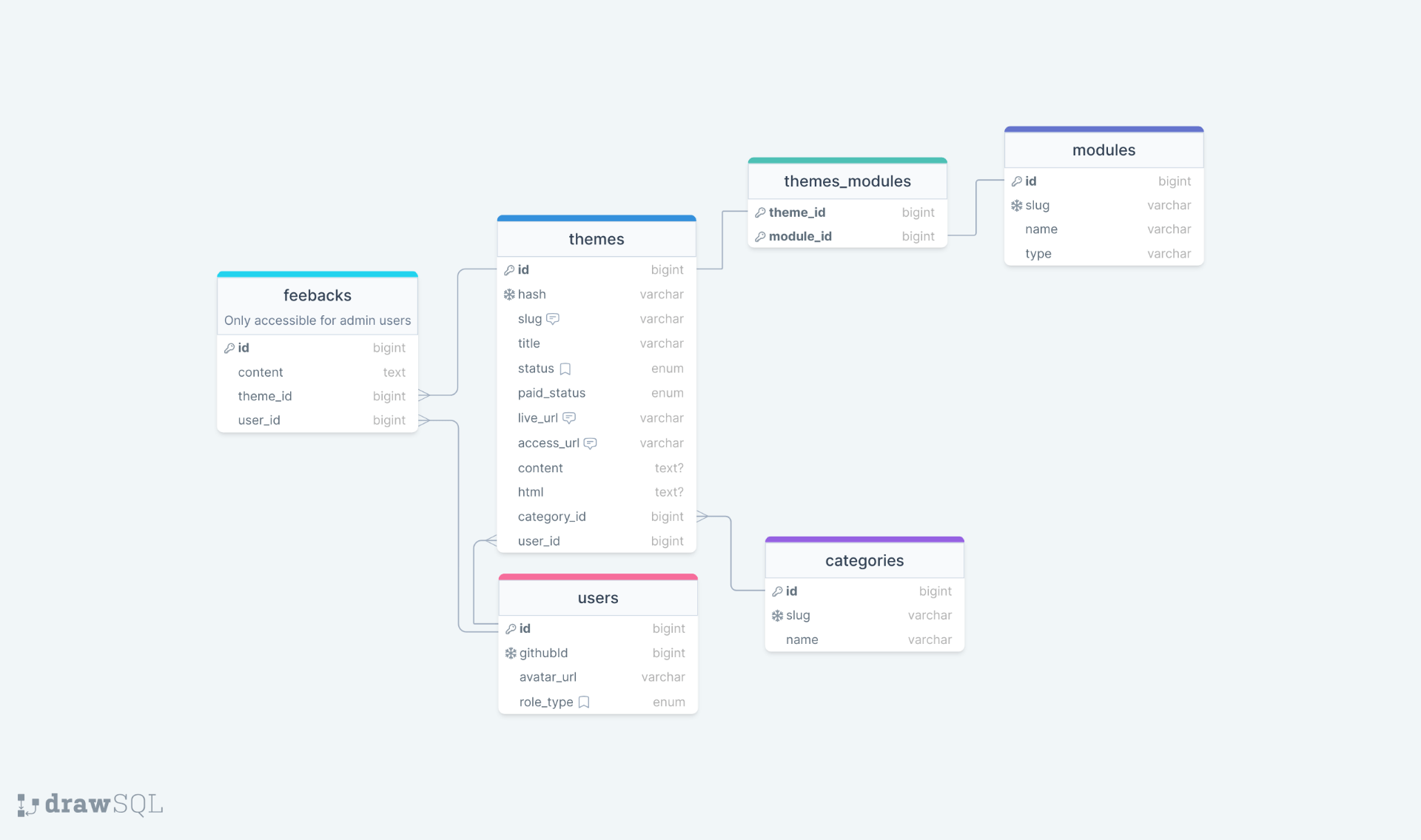
Pour construire ce schéma, j'ai utilisé drawSQL. C'est une application web pour créer des schémas SQL avec une interface utilisateur agréable. Elle est très facile à utiliser et gratuite pour les petits projets. Je la recommande.
La base de données pour le projet Orion, l'application full-stack Nuxt, est simple et courante pour ce type de projet.
- Une table
userspour stocker les utilisateurs de l'application. Stocker les utilisateurs est utile pour l'interface admin, pour bannir un utilisateur ou pour donner des droits d'administrateur. - Une table
categoriespour stocker les catégories du thème comme blog, e-commerce, documentation, etc. C'est une table simple avec un nom et un slug. Le slug est utilisé pour l'URL de la catégorie. - Une table
modulespour stocker les modules du thème. La table aura un nom, un slug et un type (officiel, communauté). Cela sera utile pour filtrer les thèmes par modules. - Une table
themespour stocker le contenu principal de l'application. Elle aura de nombreuses colonnes, mais nous verrons cela dans un autre stream. - Une table
feedbackspour stocker les retours des administrateurs sur un thème. En effet, un thème doit être évalué avant d'être publié et les retours seront utilisés pour indiquer au créateur ce qu'il doit améliorer.
Ce schéma est un bon point de départ pour clarifier les choses et savoir où commencer, mais je sais déjà qu'il évoluera.
Nuxt UI et Nuxt UI Pro
Nuxt UI est une bibliothèque de composants créée par l'équipe de Nuxt. Initialement, c'était un outil interne pour leurs propres projets comme Volta. En mai 2023, ils ont décidé de le rendre open-source et de le rendre disponible gratuitement pour tout le monde. Aujourd'hui, Nuxt UI est mon choix de prédilection pour construire des interfaces utilisateur avec Nuxt car il est simple, beau et pourtant très personnalisable.
Nuxt UI Pro est construit sur Nuxt UI et fournit des composants liés aux mises en page, comme une page, un hero, un en-tête et des mises en page complètes comme un tableau de bord, un blog, une documentation, etc. C'est un produit payant, mais il en vaut la peine. Je l'utilise pour Orion, l'application full-stack, car il fait gagner du temps et est magnifique. Le mieux, c'est qu'il est gratuit pendant le développement (le processus de build nécessitera une clé), donc vous pouvez l'essayer avant de l'acheter.
Pendant le stream, j'ai commencé par installer Nuxt UI et Nuxt UI Pro. J'ai ensuite créé la mise en page pour l'interface d'administration et la page pour les catégories. Voyons le code.
Mise en Page Admin
Avec Nuxt UI Pro, cette partie a été très facile. Il n'y a pas encore de navbar ni de sidebar. L'objectif est d'ajouter des fonctionnalités et des composants étape par étape, selon les besoins, et d'éviter de trop anticiper. Voici le code pour la mise en page layouts/admin.vue.
<template>
<UDashboardLayout>
<slot />
</UDashboardLayout>
</template>Page des Catégories
Avant de développer la vue, j'ai créé l'endpoint API pour obtenir et mettre à jour les catégories.
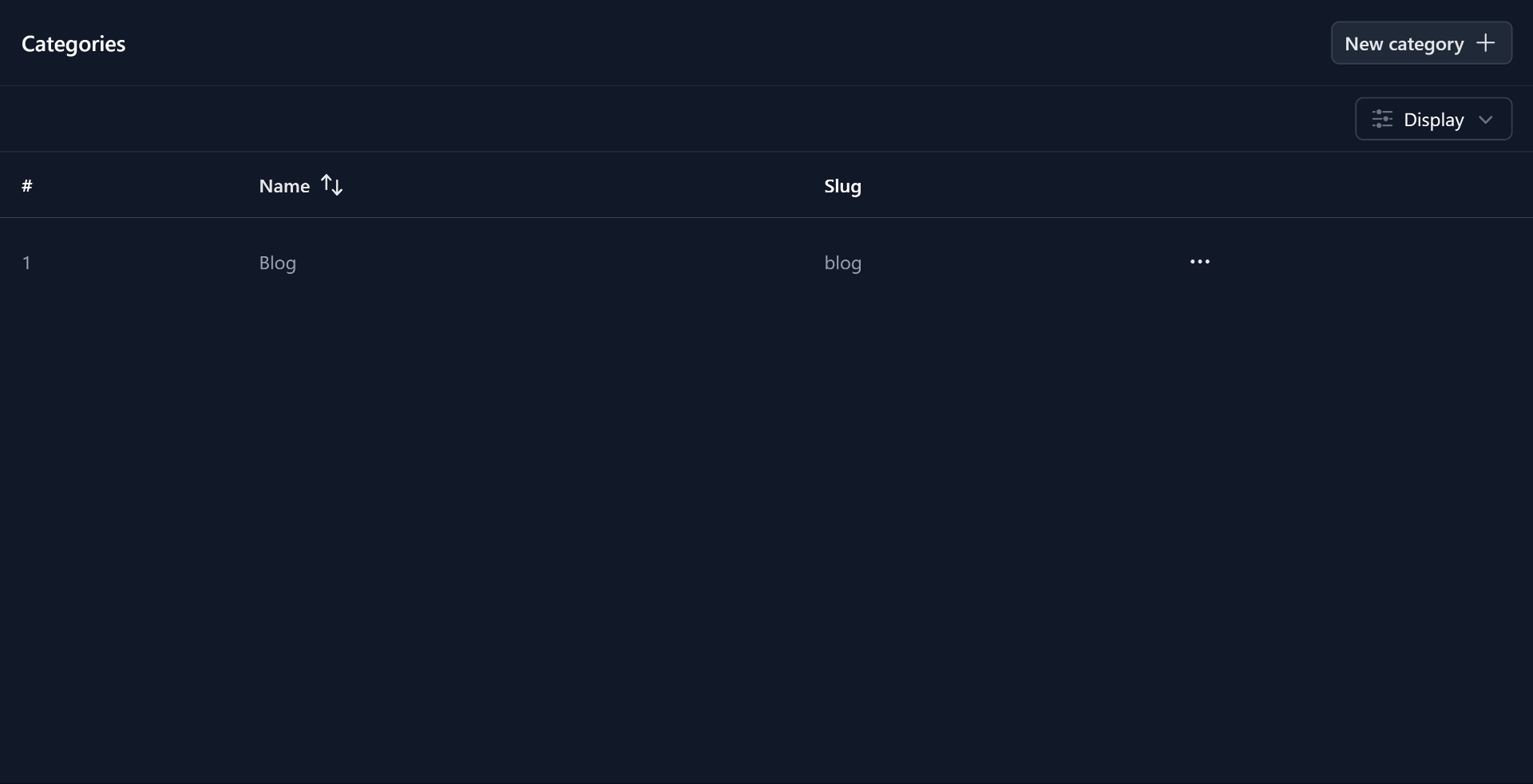
API des Catégories
Grâce à Nitro et Drizzle (configuré dans le premier stream), c'est très simple. Dans le fichier server/api/categories/index.get.ts (le .get. est utilisé pour spécifier le verbe HTTP), j'ai écrit le code suivant :
export default defineEventHandler(async () => {
const categories = await useDrizzle().select({
id: tables.categories.id,
slug: tables.categories.slug,
name: tables.categories.name
}).from(tables.categories)
return categories
})L'utilitaire useDrizzle est un wrapper autour de l'ORM Drizzle. Ce code renverra toutes les catégories avec seulement les champs id, slug, et name. C'est une bonne pratique de ne renvoyer que les champs dont vous avez besoin pour éviter d'envoyer trop de données.
Ensuite, j'ai créé l'endpoint pour créer une nouvelle catégorie, et c'est le même processus. J'ai créé le fichier server/api/categories/index.post.ts avec le code suivant :
export default defineEventHandler(async (event) => {
const body = await readBody(event)
await useDrizzle().insert(tables.categories).values({
slug: useSlugify(body.name),
name: body.name,
}).execute()
return body
})Dans ce code, il n'y a pas de vérification de sécurité, et chaque utilisateur peut créer une catégorie. Ce n'est clairement pas un cas d'utilisation pour notre application, mais la vérification sera ajoutée plus tard. En même temps, je n'ai pas vérifié le corps de la requête. Il est important de valider les données reçues d'un client pour éviter les problèmes de sécurité. Ce sera le sujet du prochain stream.
Contenu des Catégories
La page des catégories est construite avec Nuxt UI Pro, ce qui rend le code très simple.
<script setup lang="ts">
definePageMeta({
layout: 'admin'
})
</script>
<template>
<UDashboardPage>
<UDashboardPanel grow>
<!-- Contenu -->
</UDashboardPanel>
</UDashboardPage>
</template>Dans le UDashboardPanel, nous pouvons ajouter un en-tête avec le titre de la page, un bouton pour créer une nouvelle catégorie, et un tableau pour afficher les catégories.
Commençons par ajouter le tableau dans le UDashboardPanel :
<script setup lang="ts">
const columns = [{
key: 'id',
label: '#'
}, {
key: 'name',
label: 'Nom',
sortable: true
}, {
key: 'slug',
label: 'Slug',
}]
const { data: categories, pending } = await useFetch('/api/categories', {
deep: false,
})
</script>
<template>
<UTable :columns="columns" :rows="categories" :loading="pending" />
</template>C'est difficile d'être plus simple ! Merci à Nuxt UI pour ce travail !
Ensuite, ajoutons l'en-tête avec le titre et le bouton pour créer une nouvelle catégorie :
<template>
<UDashboardNavbar
title="Catégories"
>
<template #right>
<UButton
label="Nouvelle catégorie"
trailing-icon="i-heroicons-plus"
color="gray"
/>
</template>
</UDashboardNavbar>
</template>Toujours très facile. Le bouton sera utilisé pour ouvrir un modal avec un formulaire pour créer une nouvelle catégorie. J'ai commencé à créer le formulaire mais de manière très simple :
<script lang="ts" setup>
import type { FormSubmitEvent } from '#ui/types'
import type { output } from 'zod'
import { object, string } from 'zod'
const schema = object({
name: string({ message: 'Requis' }),
})
type Schema = output<typeof schema>
const state = reactive({
name: undefined,
})
async function onSubmit(event: FormSubmitEvent<Schema>) {
await $fetch('/api/categories', {
method: 'POST',
body: event.data,
})
}
</script>
<template>
<UForm :schema="schema" :state="state" @submit="onSubmit">
<UFormGroup label="Nom" name="name">
<UInput v-model="state.name" />
</UFormGroup>
<UButton type="submit">
Soumettre
</UButton>
</UForm>
</template>J'utilise le formulaire tel qu'expliqué dans la documentation de Nuxt UI. Je n'ai pas vraiment choisi Yup pour la validation mais c'était la première option proposée. Nous verrons si c'est un bon choix à l'avenir. Dans la méthode onSubmit, je fais simplement une requête fetch à l'API pour créer une nouvelle catégorie. Dans le prochain stream, nous l'améliorerons en gérant les états de succès et d'erreur.
Ce composant est placé dans un modal en utilisant le composant UModal et en écoutant l'événement de clic sur le bouton pour ouvrir le modal.
Un point sur lequel je ne suis pas sûr est la gestion de la réponse de l'API. Devrais-je retourner la nouvelle catégorie et l'ajouter dans le tableau, ou devrais-je rafraîchir le tableau ? Pour le moment, j'ai opté pour la seconde solution.
Utiliser Nuxt UI m'aide à construire l'interface admin rapidement, sans avoir besoin de composants personnalisés.
Fin du Stream
C'était définitivement un bon stream. Le projet avance sans trop de difficultés et c'est un plaisir de travailler dessus. J'attends avec impatience le prochain stream pour continuer à travailler sur l'interface admin et les formulaires. Nuxt UI et Nuxt UI Pro sont des changeurs de jeu : code simple, facile à utiliser, et je peux me concentrer sur les fonctionnalités de l'application.
Le projet est open-source et disponible sur GitHub à orion ! Donnez-lui une étoile si vous l'aimez ! ⭐
Continuons l'Interface Admin

Orion est une application full-stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir la rediffusion sur YouTube et le code source est open-source sur GitHub.
Lors du stream précédent, j'ai commencé à créer la page des catégories. J'ai mis en place les endpoints API pour obtenir et créer des catégories, et j'ai construit l'interface utilisateur pour afficher les catégories et le formulaire pour en créer une nouvelle. Dans ce stream, j'ai continué à travailler sur l'interface admin en ajoutant le formulaire de modification de catégorie et en créant une nouvelle page pour gérer les utilisateurs. J'ai également ajouté le bouncer pour sécuriser l'accès à la partie admin de l'application, tant pour le frontend que pour le backend. Voyons les travaux réalisés en détail.
Formulaire de Modification de Catégorie
Cette partie était très similaire au formulaire de création de catégorie. Au lieu de soumettre les données du formulaire à l'API pour créer une nouvelle catégorie, j'ai changé l'endpoint pour mettre à jour une catégorie existante.
J'ai créé le formulaire dans un nouveau composant components/categories/CategoryEditForm.vue (et renommé le précédent formulaire en CategoryCreateForm.vue). J'ai également créé un nouvel endpoint server/api/categories/[id].put.ts pour mettre à jour une catégorie. Cet endpoint met à jour une catégorie en utilisant l'id dans l'URL et le corps de la requête :
export default defineEventHandler(async (event) => {
const body = await readBody(event)
await useDrizzle().update(tables.categories).set({
slug: useSlugify(body.name),
name: body.name,
}).where(eq(tables.categories.id, params.id)).execute()
return sendNoContent(event, 200)
})Le code de statut 200 pourrait ne pas être le meilleur choix (204 est mieux pour un PUT), mais je réfléchis encore à savoir si je devrais retourner la catégorie mise à jour ou non.
J'ai également tenté de valider le corps de la requête en utilisant Yup, car c'était l'outil utilisé dans le frontend. Cependant, j'ai rapidement réalisé qu'il n'était pas possible de caster une chaîne en nombre. Je sais que myzod peut le faire, alors je l'ai essayé. J'ai rencontré un problème et j'ai donc utilisé Zod. J'ai déplacé le frontend vers Zod en dehors du stream.
Page des Utilisateurs
En réalité, lorsqu'un utilisateur se connecte, les données associées de GitHub sont stockées dans la base de données (en écrivant cette partie, je me demande si cela est nécessaire car cela signifie qu'une connexion est une opération d'écriture, ce qui est plus coûteux qu'une lecture) et dans la session. Ce comportement est utile pour promouvoir l'utilisateur au statut d'admin ou pour bannir un utilisateur. Mais pour le moment, il n'y a pas de moyen de gérer les utilisateurs. Donc, j'ai créé une nouvelle page pour gérer les utilisateurs. Comme la page des catégories, la page affichera les utilisateurs dans un tableau. Cependant, il ne sera pas possible de créer ou de mettre à jour un utilisateur pour le moment.
Pour récupérer les utilisateurs depuis la base de données, j'ai créé l'endpoint API server/api/users/index.get.ts :
export default defineEventHandler(async (event) => {
const users = await useDrizzle().select({
id: tables.users.id,
githubId: tables.users.githubId,
username: tables.users.username,
roleType: tables.users.roleType
}).from(tables.users)
return users
})Pour les afficher, j'utilise le composant UTable de Nuxt UI Pro. Le code est très similaire à celui de la page des catégories :
<script lang="ts" setup>
const columns = [{
key: 'id',
label: '#'
}, {
key: 'githubId',
label: 'GitHub ID',
}, {
key: 'username',
label: 'Nom d\'utilisateur',
sortable: true
}, {
key: 'roleType',
label: 'Type de rôle'
}]
const { data: users } = await useFetch('/api/users', {
deep: false,
})
</script>
<template>
<UDashboardPage>
<UDashboardPanel grow>
<UTable :columns="columns" :rows="users">
<template #roleType-data="{ row }">
<UBadge variant="subtle" :color="row.roleType === 'admin' ? 'amber' : 'primary'">
{{ row.roleType }}
</UBadge>
</template>
</UTable>
</UDashboardPanel>
</UDashboardPage>
</template>Comme prévu, le code est très similaire à celui de la page des catégories.
Maintenant que nous avons deux pages, une pour les catégories et une pour les utilisateurs, j'ai ajouté une barre latérale pour naviguer entre elles. Rien de compliqué ici, j'ai simplement utilisé le composant UDashboardSidebar de Nuxt UI Pro et ajouté les liens vers les pages des catégories et des utilisateurs :
<script lang="ts" setup>
const links = [{
id: 'categories',
label: 'Catégories',
icon: 'i-heroicons-tag',
to: '/admin/categories',
tooltip: {
text: 'Catégories',
}
}, {
id: 'users',
label: 'Utilisateurs',
icon: 'i-heroicons-user-group',
to: '/admin/users',
tooltip: {
text: 'Utilisateurs',
}
}]
</script>
<template>
<UDashboardLayout>
<UDashboardPanel>
<UDashboardSidebar>
<UDashboardSidebarLinks :links="links" />
</UDashboardSidebar>
</UDashboardPanel>
<slot />
</UDashboardLayout>
</template>Sécuriser la Partie Administration
Lors de la construction de la partie administration d'une application, il est crucial de sécuriser et de restreindre l'accès, tant pour le frontend que pour le backend. Cela signifie que seuls les utilisateurs autorisés peuvent visualiser et manipuler les données.
Pour restreindre l'accès à la partie UI de l'administration, c'est-à-dire le frontend, j'ai utilisé un middleware. Il s'agit d'une fonction qui s'exécute avant la navigation vers la page et peut être utilisée pour vérifier si l'utilisateur est authentifié et dispose des bonnes permissions. Dans ce cas, j'ai créé un middleware middleware/admin.ts pour vérifier si l'utilisateur est authentifié et a le rôle d'admin :
export default defineNuxtRouteMiddleware(() => {
const { user } = useUserSession()
const isAdmin = user.value?.roleType === 'admin'
if (!isAdmin)
return redirectTo('/')
})Le middleware doit être utilisé sur les pages nécessitant une protection en utilisant definePageMeta.
Je récupère l'utilisateur depuis la session en utilisant useUserSession et vérifie si l'utilisateur a le rôle d'admin. Sinon, je redirige l'utilisateur vers la page d'accueil.
Le backend est beaucoup plus critique que le frontend, mais il n'est pas plus difficile à sécuriser. Pour ce faire, j'ai créé un utilitaire nommé requireAdminUser dans le fichier server/utils/session.ts :
import type { UserSessionRequired } from '#auth-utils'
import type { H3Event } from 'h3'
export async function requireAdminUser(event: H3Event): Promise<UserSessionRequired> {
const userSession = await getUserSession(event)
if (!userSession.user || userSession.user.roleType !== 'admin') {
throw createError({
statusCode: 401,
message: 'Unauthorized',
})
}
return userSession as UserSessionRequired
}Cette fonction vérifie si l'utilisateur est authentifié et possède le rôle d'admin. Sinon, elle renvoie une erreur avec un code de statut 401. Cette fonction est utilisée dans les endpoints API pour les sécuriser :
export default defineEventHandler(async (event) => {
await requireAdminUser(event)
// Code pour gérer la requête
})Avec ces deux fonctions, le frontend et le backend de la partie admin sont sécurisés. Seuls les utilisateurs authentifiés avec le rôle d'admin peuvent accéder à la partie administration de l'application.
À Venir
Ce stream a été très productif et a mis en place des éléments importants pour l'avenir. Le prochain stream sera consacré aux modules et au créateur de thèmes. J'espère vraiment pouvoir mettre cela en production bientôt. Je suis vraiment impatient de voir les retours de la communauté.
Le projet est open-source et disponible sur GitHub à orion ! Donnez-lui une étoile si vous l'aimez ! ⭐
Récupérer une API externe pour les modules

Orion est une application full-stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir le replay sur YouTube et le code source est open-source sur GitHub.
Avant de continuer et d'implémenter la page des modules, j'ai décidé de modifier le comportement de useFetch sur les pages actuelles des Catégories et des Utilisateurs. En effet, le bloc composable useFetch bloque la navigation côté client jusqu'à ce que les données soient récupérées. Cela donne la sensation d'une application lente. Pour éviter cela, je peux utiliser le drapeau lazy. Côté serveur, cela ne change rien et la page sera toujours servie avec les données. Côté client, la navigation sera instantanée et j'afficherai un squelette pendant que les données sont en cours de récupération en utilisant le pending ref.
const { data, pending } = await useFetch('/api/categories', {
deep: false,
lazy: true, // <= Ne bloque pas la navigation
default: () => []
})Le pending ref est un booléen qui indique si les données sont en cours de récupération ou non. Je le passe simplement aux props loading du composant UTable de Nuxt UI Pro et voilà ! L'utilisateur verra un loader pendant que les données sont en cours de récupération et la navigation sera instantanée.


Page des Modules
Les modules sont des modules Nuxt. Ils seront liés aux thèmes et seront utilisés pour filtrer les thèmes. Imaginez que vous recherchez un thème avec un bon SEO et précisément un sitemap, vous pourrez filtrer les thèmes en fonction des modules qu'ils utilisent. C'est l'objectif de la fonctionnalité des modules. Cela aidera également l'utilisateur à comprendre comment le thème est construit et quelles sont les fonctionnalités.
La première chose que je fais est d'ajouter une nouvelle page pages/admin/modules.vue. Ensuite, j'ajoute le tableau pour afficher les modules et les métadonnées de la page pour utiliser la mise en page admin et le middleware admin. C'est similaire aux pages des catégories et des utilisateurs, donc je ne vais pas le détailler ici.
Remplir la Base de Données
La question principale est : comment remplir la base de données avec les modules ? Pour les catégories, je les crée manuellement. Cela convient car il n'y a pas beaucoup de catégories et il n'y a pas de moyen d'obtenir une liste prédéfinie, mais pour les modules, c'est différent. Les modules sont créés par l'équipe principale ou la communauté et il y en a beaucoup. De plus, la liste n'est pas statique et peut changer au fil du temps. Donc, je dois trouver une API pour récupérer les modules. Heureusement, Nuxt a une API pour obtenir la liste des modules : api.nuxt.com/modules. Cette API n'est pas documentée mais elle est publique et je peux l'utiliser.
Grâce à cette API, je pourrai récupérer les données, les assainir pour ne garder que les informations utiles et les stocker dans la base de données. Je vais créer un point de terminaison, accessible uniquement à l'admin, pour récupérer les modules et les stocker dans la base de données. Un deuxième point de terminaison sera disponible pour récupérer les modules depuis la base de données. Cela sera utile pour le frontend afin d'afficher les modules.
Récupération de l'API Externe
Je crée un point de terminaison server/api/modules/fetch.post.ts (hors stream, j'ai trouvé que nommer ce point de terminaison sync était une meilleure idée) pour récupérer les modules depuis l'API externe et les stocker dans la base de données.
Tout d'abord, j'ajoute l'utilitaire requireAdminUser pour sécuriser le point de terminaison. Ensuite, je récupère les modules depuis l'API externe en utilisant la fonction globale $fetch :
export default defineEventHandler(async (event) => {
await requireAdminUser(event)
const data = await $fetch('https://api.nuxt.com/modules')
})Les données retournées par l'API contiennent beaucoup de données dont je n'ai pas besoin. Je n'ai besoin que du name, repo, type, et icon des modules. Donc, j'assainis les données pour ne garder que les informations utiles :
const modules = data.modules
.map(({ name, type, icon, repo }) => ({ name, type, icon, repo }))
.filter(({ type }) => type === 'official' || type === 'community')Je choisis de ne pas garder le type third party car il peut s'agir d'un module de n'importe qui et je ne connais pas la qualité de ces modules. La clé repo n'était pas prévue mais je pense que c'est une bonne idée de l'avoir. Je pourrais l'utiliser pour ajouter un lien vers le dépôt GitHub du module sur une page de thème.
Maintenant que j'ai mes modules, je dois les stocker dans la base de données, et je dois également créer la table pour les stocker. Dans le fichier server/database/schema.ts, je crée la table modules :
export const modules = sqliteTable('modules', {
id: integer('id').primaryKey({ autoIncrement: true }),
name: text('name').notNull().unique(),
repo: text('repo').notNull().unique(),
type: text('type', { enum: ['official', 'community'] }).notNull(),
icon: text('icon'),
})Note
N'oubliez pas d'exécuter la commande drizzle pour générer la migration SQL.
Dans le point de terminaison, il est maintenant possible d'insérer les modules dans la base de données :
await useDrizzle().insert(tables.modules).values(modules).execute()MAIS, surprise, cela ne fonctionne pas. Je ne le savais pas, mais le Cloudflare D1 a une limite (ou plusieurs) sur les paramètres liés à 100. En réalité, cette limite existe parce qu'ils utilisent SQLite en arrière-plan, ce qui a cette limite pour des raisons de sécurité.
Qu'est-ce qu'un paramètre lié ? C'est un paramètre dans une requête SQL qui est remplacé par une valeur lorsque la requête est exécutée. Par exemple, dans la requête SELECT * FROM users WHERE id = ?, le ? est un paramètre lié. Dans le cas de la requête d'insertion INSERT INTO users (name, email) VALUES (?, ?), les paramètres liés sont les valeurs à insérer dans la table. La limite est de 100 paramètres liés. Attention, une ligne n'est pas un paramètre lié, un paramètre lié est une valeur unique, ce qui signifie que si vous insérez une ligne avec 10 colonnes, cela comptera comme 10 paramètres liés. Il y a 42 modules avec 4 colonnes, donc 168 paramètres liés.
C'est un vrai problème car je devrai diviser l'insertion en plusieurs requêtes et un worker est limité dans le temps, donc s'il fonctionne trop longtemps, le worker pourrait échouer.
const columnsPerModule = Object.keys(modules[0]).length
const insertPerLoop = Math.floor(100 / columnsPerModule)
const loops = Math.ceil(modules.length / insertPerLoop)
for (let loop = 0; loop < loops; loop++) {
const values = modules.slice(loop * insertPerLoop, (loop + 1) * insertPerLoop)
await useDrizzle().insert(tables.modules).values(values).onConflictDoNothing({ target: tables.modules.repo }).execute()
}Pour avoir une insertion dynamique en cas de changement du nombre de colonnes, je calcule le nombre maximum de lignes que je peux insérer dans une seule requête. Ensuite, je boucle sur les modules et insère le nombre maximum de lignes dans chaque requête. J'utilise également la méthode onConflictDoNothing pour éviter d'insérer le même module deux fois si je fais fonctionner le point de terminaison plusieurs fois.
J'ai essayé cela dans un environnement de production, et tout fonctionne bien.
Je choisis de retourner un code de statut 204 lorsque les modules sont récupérés. Si tout est correct, je peux rafraîchir la liste des modules dans l'interface utilisateur pour voir les nouveaux modules.
Servir les Modules
Cette partie est exactement la même que le point de terminaison d'index des catégories et des utilisateurs. Je crée un point de terminaison server/api/modules/index.get.ts pour obtenir les modules de la base de données :
export default defineEventHandler(async () => {
const modules = await useDrizzle().select({
id: tables.modules.id,
name: tables.modules.name,
type: tables.modules.type,
icon: tables.modules.icon,
}).from(tables.modules)
return modules
})Rien de nouveau ici, je sélectionne simplement les modules depuis la base de données et les retourne.
Conclusion
Tout cela nous donne ce résultat :
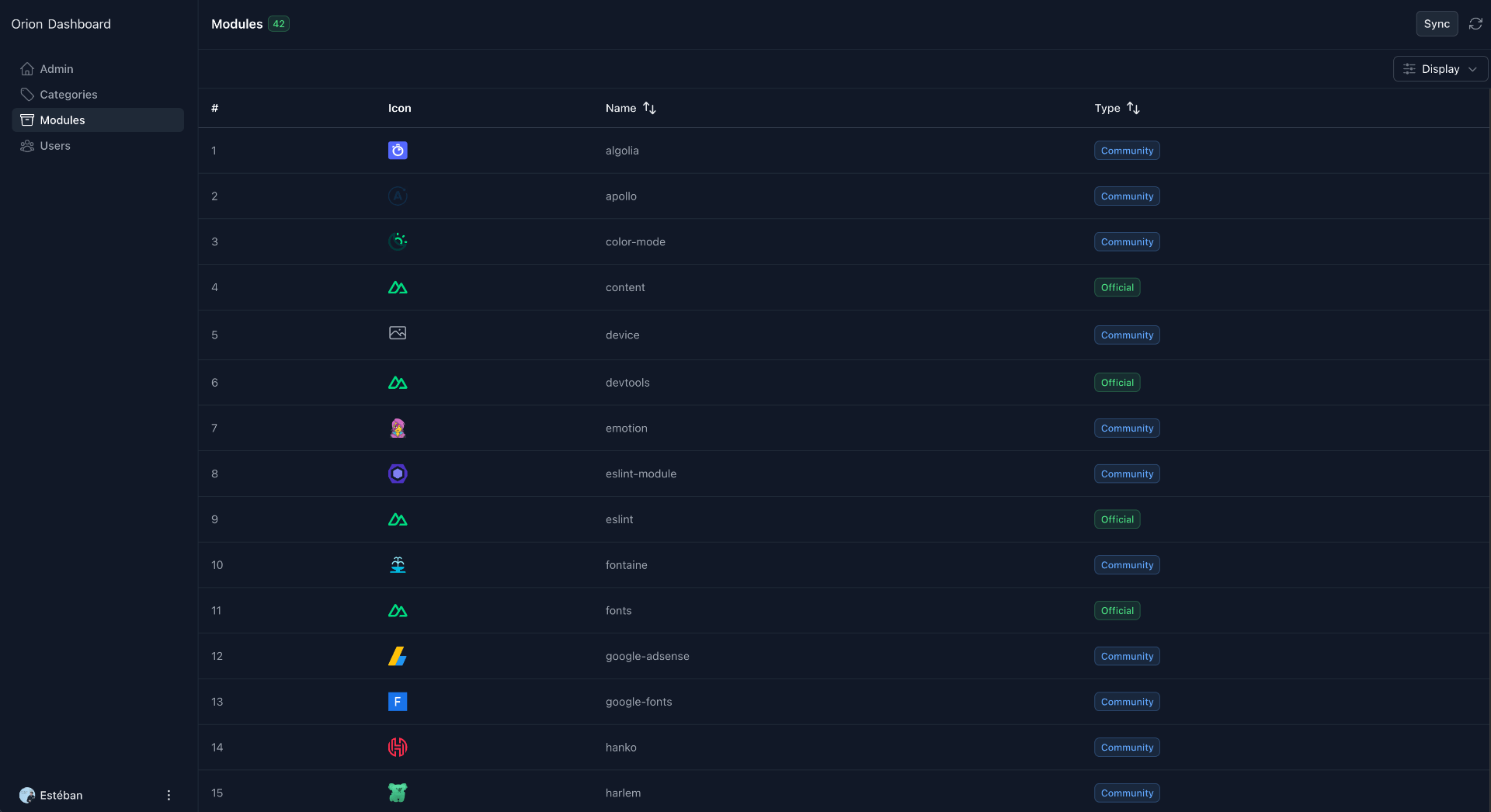
Ce stream était différent des autres. D'abord, j'ai maintenant un nouveau micro et le son est bien meilleur qu'avant !
Deuxièmement, j'ai rencontré un problème avec la limite D1 (ce qui pourrait entraîner un besoin de repenser le projet, espérons que ce ne sera pas le cas) sur les paramètres liés. C'est une bonne leçon pour moi, et j'espère que cela sera utile pour vous.
Factorisation de la Gestion des Utilisateurs
Cette partie a été réalisée hors stream car elle n'était pas intéressante à voir et je n'étais pas sûr de la direction que je voulais prendre.
En écrivant une partie de cet article, je me demande si stocker les données des utilisateurs était une bonne idée. Ne pourrait-il pas être mieux ? Cette question vient de la façon dont je gère le point de terminaison d'authentification.
En fait, lorsqu'un utilisateur se connecte, j'écris toujours les données de l'utilisateur dans la base de données pour être sûr qu'elles sont à jour. La principale préoccupation est qu'une écriture est beaucoup plus coûteuse qu'une lecture. Pour trouver des idées, j'ai lu le projet de liste de tâches Nuxt d'Atinux. Dans ce projet, il ne stocke pas les données des utilisateurs. Lorsque l'utilisateur se connecte, il ne stocke que l'ID de l'utilisateur dans le cookie. Lorsque l'utilisateur crée une tâche, il lui suffit de lire l'ID de l'utilisateur depuis le cookie pour savoir qui est l'utilisateur. C'est très intelligent et simple. Je vais faire de même. Premièrement à travers.
Analysons si cette méthode est possible pour le projet Orion. Pour savoir si c'est possible, je dois répondre à quelques questions :
- Puis-je bannir ou promouvoir un utilisateur sans stocker les données de l'utilisateur ?
- Un utilisateur peut-il créer des données sans stocker les données de l'utilisateur ?
- Puis-je afficher les données des utilisateurs sans stocker les données de l'utilisateur ?
Pour la première question, c'est oui. Je peux imaginer un système où vous entrez le login d'un utilisateur, et lorsque l'utilisateur se connecte, je rechercherai dans la base de données si l'entrée existe et obtiendrai les données pertinentes. Ce n'est pas la meilleure méthode mais c'est possible.
Pour la deuxième question, c'est oui. Puisque les données sont dans le cookie, je peux facilement savoir qui est l'utilisateur et créer des données en utilisant cette information. Et c'est ainsi que ça fonctionne en fait. Je ne récupère pas l'utilisateur pour chaque requête.
Pour la troisième question, c'est non. Imaginez que je veuille afficher le modèle créé par l'utilisateur 'X'. Dans notre schéma SQL, nous avons une colonne user_id dans la table templates. Si je ne stocke pas les données de l'utilisateur, je ne pourrai pas savoir qui est l'utilisateur 'X', associé à user_id. Je devrai stocker les données de l'utilisateur dans la base de données. Cela pourrait être possible avec une base de données non relationnelle mais ce n'est pas le cas ici. Nous pourrions aussi imaginer un système où l'utilisateur est sauvegardé lorsqu'il crée un modèle. C'est possible mais cela ajoutera beaucoup de complexité. Au final, cette réponse et celle à la question une compliquent le système pour aucun réel gain.
Maintenant que nous savons que nous devons stocker les utilisateurs dans la base de données, que pouvons-nous améliorer ?
- Sauvegarder les données des utilisateurs seulement si nécessaire. Par exemple, je pourrais d'abord rechercher l'utilisateur avant de sauvegarder ses données lorsque l'utilisateur se connecte.
- Sauvegarder l'email de l'utilisateur. Cela sera utile pour le système de feedback.
- Sauvegarder le nom de l'utilisateur et renommer la colonne
usernameenlogin. - Ajouter une colonne
created_atet une colonneupdated_at. - Mettre à jour les données stockées dans le cookie.
Avec tous ces points, je mets également à jour l'interface utilisateur en conséquence. Il n'y a rien de difficile ici ; il s'agit principalement de renommer et d'ajouter des champs dans le schéma.
export const users = sqliteTable('users', {
id: integer('id').primaryKey({ autoIncrement: true }),
githubId: integer('github_id').notNull().unique(),
email: text('email').notNull().unique(),
login: text('login').notNull().unique(),
name: text('name'),
avatarUrl: text('avatar_url').notNull(),
roleType: text('role_type', { enum: ['admin', 'creator'] }).default('creator'),
createdAt: text('created_at').notNull().$defaultFn(() => sql`(current_timestamp)`),
updatedAt: text('updated_at').notNull().$defaultFn(() => sql`(current_timestamp)`).$onUpdateFn(() => sql`(current_timestamp)`),
})Les fonctions $defaultFn et $onUpdateFn sont utilisées pour définir la valeur par défaut de la colonne. Dans le cas de createdAt, la valeur par défaut est l'horodatage actuel. Dans le cas de updatedAt, la valeur par défaut est l'horodatage actuel, et la valeur est mise à jour lorsque la ligne est mise à jour. C'est entièrement automatique et géré par Drizzle.
Je mets également à jour le server/routes/auth/github.ts pour stocker les données de l'utilisateur seulement si nécessaire :
export default oauth.githubEventHandler({
config: {
emailRequired: true,
},
async onSuccess(event, result) {
const { user: ghUser } = result
const githubId = ghUser.id
let user: User | undefined
user = await useDrizzle().select().from(tables.users).where(eq(tables.users.githubId, githubId)).get()
/**
* Si l'utilisateur n'est pas dans la base de données ou si ses données ont changé, mettre à jour les données de l'utilisateur.
* Une écriture est plus coûteuse qu'une lecture, donc nous écrivons seulement si nécessaire.
*/
if (!user || userDataChanged(user, ghUser)) {
user = await useDrizzle().insert(tables.users).values({
githubId,
login: ghUser.login,
email: ghUser.email,
name: ghUser.name,
avatarUrl: ghUser.avatar_url,
}).onConflictDoUpdate({
target: tables.users.githubId,
set: {
login: ghUser.login,
email: ghUser.email,
name: ghUser.name,
avatarUrl: ghUser.avatar_url,
},
}).returning().get()
}
/**
* Définir seulement les données nécessaires dans la session.
*/
await setUserSession(event, {
user: {
id: user.id!,
login: ghUser.login,
email: ghUser.email,
name: ghUser.name,
avatarUrl: ghUser.avatar_url,
roleType: user.roleType || 'creator',
},
})
return sendRedirect(event, '/portal')
},
})Avec cette nouvelle méthode de gestion des données des utilisateurs, je réduis le nombre d'écritures dans la base de données tout en mettant à jour les données des utilisateurs lorsque nécessaire.
Création d'un formulaire pour les modèles
Orion est une application full-stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir le replay sur YouTube et le code source est open-source sur GitHub.
Depuis le début de la série, je travaille sur l'interface d'administration de l'application web. Aujourd'hui, il est temps de créer le formulaire pour ajouter un nouveau modèle. Ce formulaire sera utilisé par les créateurs pour ajouter leurs modèles ou thèmes à la plateforme. Pour rappel, Orion est une collection de modèles alimentée par la communauté pour votre prochain projet, des pages de destination aux applications web complètes.
Schéma du modèle
N'oubliez pas que les choses évoluent et que le schéma n'est pas définitif.
Étant donné que la fonctionnalité de modèle est importante, je l'ai divisée en plusieurs streams en direct. La première étape consiste à créer le formulaire le plus simple mais fonctionnel possible et à ajouter des fonctionnalités au fil du temps. C'est pourquoi le schéma ci-dessus n'est pas exactement le même que celui que nous avons dessiné dans le schéma SQL (pas de modules, pas d'images et pas de markdown, pour l'instant).
export const templates = sqliteTable('templates', {
id: integer('id').primaryKey({ autoIncrement: true }),
hash: text('hash').notNull().unique(),
slug: text('slug').notNull(),
title: text('title').notNull(),
status: text('status', { enum: ['submitted', 'refused', 'validated'] }).notNull().default('submitted'),
paidStatus: text('paid_status', { enum: ['free', 'paid'] }).notNull().default('free'),
liveUrl: text('live_url'),
accessUrl: text('access_url').notNull(),
description: text('description').notNull(),
userId: integer('user_id').notNull().references(() => users.id),
categoryId: integer('category_id').notNull().references(() => categories.id),
})La colonne hash est un petit ID que je stockerai dans la base de données pour créer des URL comme Notion ou Dev.to : <slug>-<hash>. Cela est utile pour avoir une URL lisible, à la fois pour les humains et pour le SEO, mais comme deux modèles peuvent avoir le même nom, ou le nom d'un modèle peut changer, j'ai besoin d'un ID unique.
Pour la première fois, nous créons une relation entre deux tables : une relation un-à-plusieurs entre la table users et la table templates. Cette relation est utilisée pour savoir qui est le créateur du modèle. La colonne userId est une clé étrangère qui fait référence à la colonne id de la table users.
La colonne categoryId est également une clé étrangère qui fait référence à la colonne id de la table categories. Cette relation est utilisée pour savoir dans quelle catégorie se trouve le modèle.
Afin de pouvoir récupérer les modèles d'un utilisateur ou d'une catégorie, je dois également définir la relation dans l'autre sens. Grâce à Drizzle, c'est assez facile.
export const usersRelations = relations(users, ({ many }) => ({
templates: many(templates),
}))
export const categoriesRelations = relations(categories, ({ many }) => ({
templates: many(templates),
}))Formulaire de modèle
Pendant cette phase, je crée le formulaire sur l'UI, exactement comme je l'ai fait pour les catégories. Je définis l'état, le schéma et l'action au moment de la soumission !
Maintenant qu'un utilisateur est capable de remplir un formulaire, j'ai besoin d'un point de terminaison pour enregistrer les données dans la base de données. Je crée le point de terminaison server/api/templates/index.post.ts pour enregistrer le modèle dans la base de données :
import { number, object, string, enum as zEnum } from 'zod'
export default defineEventHandler(async (event) => {
const { user } = await requireUserSession(event)
const body = await readValidatedBody(event, object({
title: string(),
paidStatus: zEnum(['free', 'paid']),
categoryId: number(),
liveUrl: string().optional(),
accessUrl: string(),
description: string().max(1000),
}).parse)
await useDrizzle().insert(tables.templates).values({
hash: useHash(),
slug: useSlugify(body.title),
title: body.title,
categoryId: body.categoryId,
paidStatus: body.paidStatus,
liveUrl: body.liveUrl,
accessUrl: body.accessUrl,
description: body.description,
userId: user.id,
}).execute()
return sendNoContent(event, 201)
})Assez similaire au point de terminaison pour créer une nouvelle catégorie. Une différence est l'utilisation de l'utilitaire requireUserSession pour s'assurer que la demande provient d'un utilisateur authentifié et pour obtenir les données de l'utilisateur. J'utilise les données pour remplir la colonne userId dans la table templates. Bien sûr, je valide les données reçues du client à l'aide de Zod.
L'utilitaire useHash est un petit wrapper autour du package nanoid.
Modèles dans l'Interface d'Administration
Pendant cette partie, j'ai rencontré un bug important. Lisez attentivement la partie suivante, cela pourrait vous faire gagner beaucoup de temps si vous prévoyez également d'utiliser Drizzle sur Cloudflare.
Les utilisateurs sont capables de créer des modèles, c'est bien. Pour les surveiller et les approuver, je dois créer une page dans l'interface d'administration pour gérer les modèles. Cette page affichera les modèles dans un tableau et permettra à l'administrateur de les approuver ou de les refuser. Je n'implémente que la vue, pas l'action. La tâche est simple, c'est comme toute autre page dans l'interface d'administration. Si seulement je savais...
Tout d'abord, créons le point de terminaison pour obtenir les modèles depuis la base de données. Je crée le point de terminaison server/api/templates/index.get.ts :
export default defineEventHandler(async () => {
const templates = await useDrizzle()
.select()
.from(tables.templates)
.leftJoin(tables.users, eq(tables.templates.userId, tables.users.id))
.leftJoin(tables.categories, eq(tables.templates.categoryId, tables.categories.id))
return templates
})Ce point de terminaison récupère tous les modèles de la base de données et les remplit à l'aide d'une jointure et de la relation que nous avons définie plus tôt dans le schéma.
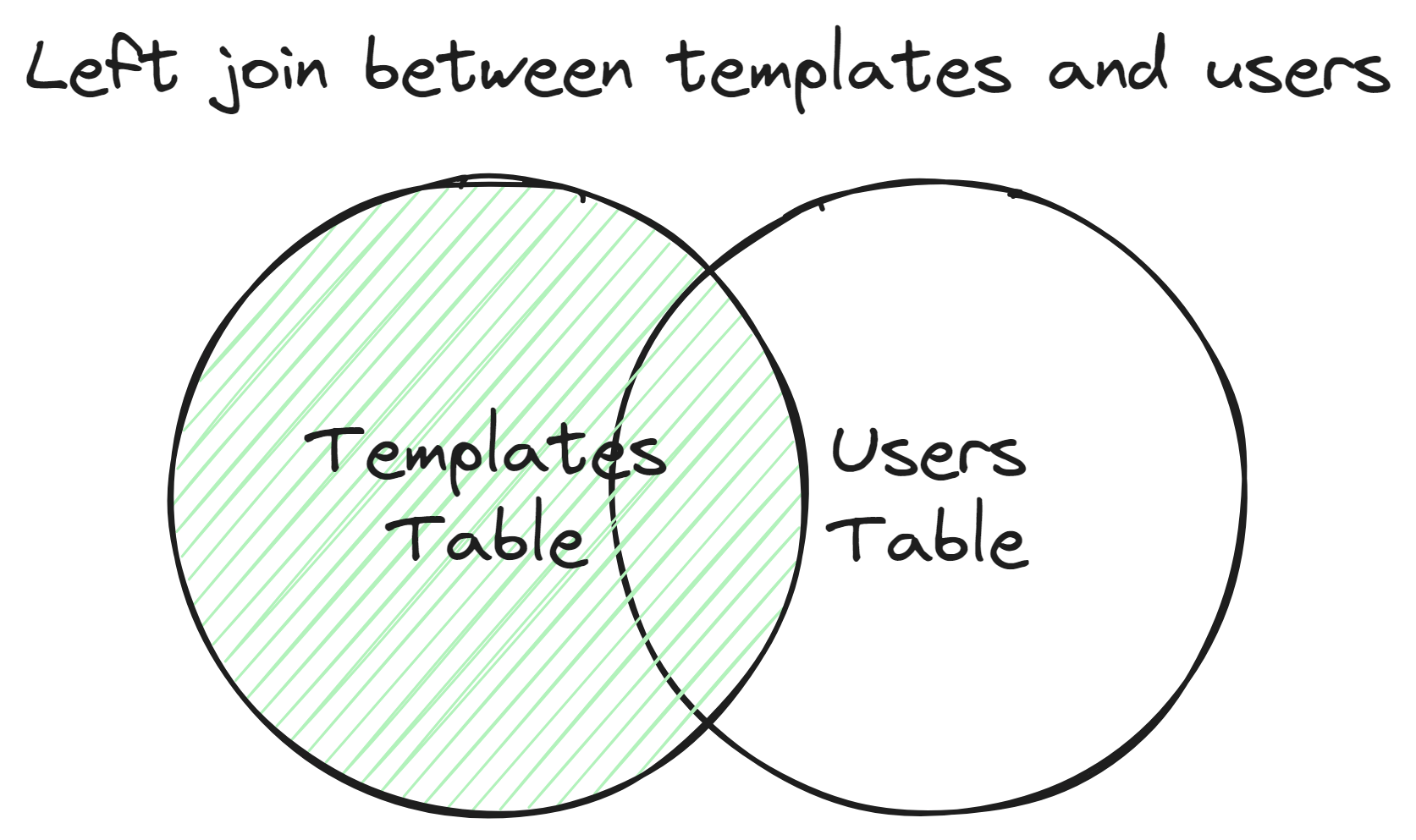
Une jointure est une opération SQL qui combine les lignes de deux ou plusieurs tables en fonction d'une colonne liée entre elles. Dans ce cas, je fais une jointure de la table templates avec la table users et la table categories. La méthode leftJoin est utilisée pour conserver toutes les lignes de la table templates, même s'il n'y a pas de correspondance dans les tables users ou categories.
Maintenant que j'ai les données, je peux les afficher sur l'UI. J'utilise le composant UTable de Nuxt UI Pro pour afficher les modèles dans un tableau :
<script lang="ts" setup>
const columns = [{
key: 'id',
label: '#',
}, {
key: 'title',
label: 'Title',
sortable: true,
}, {
key: 'status',
label: 'Status',
sortable: true,
}, {
key: 'paidStatus',
label: 'Paid Status',
sortable: true,
}, {
key: 'liveUrl',
label: 'Live URL',
}, {
key: 'accessUrl',
label: 'Access URL',
}, {
key: 'description',
label: 'Description',
}, {
key: 'category',
label: 'Category',
}, {
key: 'createdBy',
label: 'Created By',
}]
const { data: templates, refresh, pending } = await useFetch('/api/templates', {
deep: false,
lazy: true,
default: () => [],
})
</script>
<template>
<UTable
:columns="columns"
:rows="templates"
:loading="pending"
>
<template #liveUrl-data="{ row }">
<UButton
v-if="row.liveUrl"
variant="link"
target="_blank"
:to="row.liveUrl"
class="flex flex-row items-center gap-1"
>
<span>{{ row.liveUrl }}</span>
<span class="i-heroicons-arrow-top-right-on-square-16-solid inline-block h-4 w-4" />
</UButton>
<span v-else> - </span>
</template>
<template #accessUrl-data="{ row }">
<UButton
variant="link"
target="_blank"
:to="row.accessUrl"
class="flex flex-row items-center gap-1"
>
<span>{{ row.accessUrl }}</span>
<span class="i-heroicons-arrow-top-right-on-square-16-solid inline-block h-4 w-4" />
</UButton>
</template>
<template #paidStatus-data="{ row }">
<template v-if="row.paidStatus === 'free'">
<UBadge
color="green"
variant="subtle"
>
Free
</UBadge>
</template>
<template v-else-if="row.paidStatus === 'paid'">
<UBadge
color="yellow"
variant="subtle"
>
Paid
</UBadge>
</template>
</template>
<template #createdBy-data="{ row }">
<div class="flex flex-row items-center gap-2">
<img
:src="row.user.avatarUrl"
alt="avatar"
class="h-6 w-6 rounded-full"
>
<span>{{ row.user.name ?? row.user.login }}</span>
</div>
</template>
<template #category-data="{ row }">
{{ row.category.name }}
</template>
</UTable>
</template>Mais cela ne fonctionne pas. Étant habitué à Adonis, j'étais familiarisé avec un objet comme celui-ci :
{
"id": 1,
"title": "My template",
"status": "submitted",
"liveUrl": "https://example.com",
"user": {
"id": 1,
"name": "John Doe",
"avatarUrl": "https://example.com/avatar.jpg"
},
"category": {
"id": 1,
"name": "Landing Page"
}
}Mais j'ai reçu un objet comme celui-ci :
{
"template": {
"id": 1,
"title": "My template",
"status": "submitted",
"liveUrl": "https://example.com"
},
"user": {
},
"category": {
}
}et quelle surprise de voir que les clés et les valeurs étaient échangées entre elles. Difficile à expliquer mais voyez l'exemple.
{
"template": {
"id": "My template",
"status": "https://example.com"
},
"user": {
"id": "John Doe",
"login": "https://avatars.github.com/u/1"
}
}Très difficile de manipuler les données maintenant ! L'ID devrait être un nombre et le login ne devrait définitivement pas être une URL.
Après une longue recherche, j'ai trouvé deux problèmes : https://github.com/cloudflare/workers-sdk/issues/3160 et https://github.com/drizzle-team/drizzle-orm/issues/555 expliquant pourquoi cela ne fonctionne pas. Lorsque deux tables ont le même nom de colonne, Drizzle et Cloudflare sont incapables de les résoudre correctement et mélangent les données. La solution consiste à sélectionner explicitement les colonnes et à renommer les colonnes similaires.
const templates = await useDrizzle().select({
id: tables.templates.id,
title: tables.templates.title,
description: tables.templates.description,
status: tables.templates.status,
paidStatus: tables.templates.paidStatus,
liveUrl: tables.templates.liveUrl,
accessUrl: tables.templates.accessUrl,
user: {
name: tables.users.name,
login: tables.users.login,
avatarUrl: tables.users.avatarUrl,
},
category: {
name: sql<string>`${tables.categories.name}`.as('c_name'),
},
}).from(tables.templates).leftJoin(tables.users, eq(tables.templates.userId, tables.users.id)).leftJoin(tables.categories, eq(tables.templates.categoryId, tables.categories.id))sql<string>'${tables.categories.name}'.as('c_name') est le code important. Je renomme la colonne name en c_name pour éviter le conflit. J'utilise également cette syntaxe pour formater l'objet avec les clés user et category. Maintenant, tout fonctionne comme prévu.
Conclusion
Travailler sur le côté client, et pas seulement sur la partie admin, rend le projet encore plus concret. Il reste encore beaucoup de travail sur le formulaire de modèle comme le markdown ou l'image, mais c'est un très bon début.
J'apprécie vraiment ce projet et j'espère que vous aussi.
Poursuivre le modèle de formulaire

Orion est une application full-stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir la rediffusion sur YouTube et le code source est open-source sur GitHub.
Ce direct était court, donc j'essaie de faire des choses intéressantes. Je fais principalement trois choses :
- Créer la page de modèle de l'émission
- Gérer le markdown côté serveur pour la description du modèle
- Ajouter un éditeur de markdown pour la description du modèle
Voyons comment ça se passe. Pendant le direct, ça se passe bien mais depuis, j'ai complètement réécrit la partie éditeur de markdown.
Page de modèle de l'émission
Cet élément était davantage lié à l'utilisation de l'URL qu'au design de la page. En effet, l'URL fonctionnera comme Notion ou Dev.to : /<slug>-<hash> où le slug est le nom du modèle et le hash est un identifiant unique. Le slug est utilisé pour le SEO et le hash est utilisé pour obtenir le modèle. Le slug n'est pas unique et peut changer avec le temps. Le hash est unique et sert à obtenir le modèle.
Sur la page, nous commençons par obtenir les paramètres de la route :
const route = useRoute()
const slug = route.params.slug // <slug>-<hash>La variable slug contient à la fois le slug du modèle et le hash. Nous savons que le hash fait exactement 12 caractères donc nous pouvons découper le slug pour obtenir le slug et le hash :
slug.slice(-12)Enfin, nous pouvons faire une requête au backend pour récupérer le modèle. Tout cela nous donne ce code :
<script lang="ts" setup>
const route = useRoute()
const hash = computed(() => {
return (route.params.slug as string).slice(-12)
})
const { data: template } = await useFetch(`/api/templates/${hash.value}`, {
deep: false,
})
</script>
<template>
<article
v-if="template"
>
{{ template }}
</article>
</template>La partie serveur n'est pas si compliquée puisque nous obtenons seulement le hash à partir du paramètre de route et recherchons le modèle en utilisant une clause where :
import { object, string } from 'zod'
export default defineEventHandler(async (event) => {
const params = await getValidatedRouterParams(event, object({
hash: string().length(12),
}).parse)
const { hash } = params
const template = await useDrizzle().select().from(tables.templates).where(eq(tables.templates.hash, hash))
return template
})Plus tard, nous devrons joindre les données de l'utilisateur et les données de la catégorie pour avoir un modèle complet.
Markdown côté serveur
L'idée de recevoir du markdown du client est de le nettoyer facilement pour éviter les injections HTML.
Imaginez si le client envoie ce code HTML :
<p> Hello World!</p>
<script> console.log('hacked') </script>Si le serveur stocke ce contenu dans la base de données et l'affiche ensuite en utilisant la directive v-html, chaque utilisateur qui verra la page exécutera le script. C'est un réel problème de sécurité.
En recevant du markdown du client, je peux facilement le transformer en utilisant markdown-it et stocker le HTML nettoyé dans la base de données. Le HTML nettoyé est du HTML qui ne contient aucun script ou balise dangereuse.
Pour ce faire, je dois installer markdown-it et mettre à jour le point de terminaison pour créer un modèle server/api/templates/index.post.ts. J'ajoute également une nouvelle colonne descriptionHTML au schéma pour stocker le HTML nettoyé. Stocker le HTML évite de le faire chaque fois que nous rendons la page.
await useDrizzle().insert(tables.templates).values({
hash: useHash(),
slug: useSlugify(body.title),
title: body.title,
categoryId: body.categoryId,
paidStatus: body.paidStatus,
liveUrl: body.liveUrl,
accessUrl: body.accessUrl,
description: body.description,
descriptionHTML: useMarkdown(body.description),
userId: user.id,
}).execute()La fonction useMarkdown est une fonction simple qui utilise markdown-it pour transformer le markdown en HTML.
Éditeur de Markdown
Cette partie est très expérimentale et pourrait changer à l'avenir. Il s'agit d'une première implémentation.
En écrivant cette partie, j'ai fait quelques recherches supplémentaires et tout va changer. Je pense que c'est encore intéressant de voir le processus.
Avant de commencer, je dois faire un choix. Quel éditeur de markdown devrais-je utiliser ? Rappelez-vous que nous venons de mettre en place un point de terminaison serveur pour gérer le markdown. J'ai de nombreuses options :
- SimpleMDE
- EasyMDE
- TinyMDE
- Editor.js
- Quill
- Trix
- CKEditor
- TinyMCE
C'est beaucoup d'options. Mais, quels sont mes besoins ? J'ai besoin d'un éditeur très simple qui peut retourner du markdown. Ça a l'air facile, non ?
Editor.js, CKEditor et TinyMCE sont des éditeurs avancés donc je ne les utiliserai pas. SimpleMDE est une bonne option mais trop vieux. Il n'a pas reçu de mises à jour depuis 6 ans. SimpleMDE et TinyMDE sont des forks de SimpleMDE. EasyMDE est puissant, simple et retourne du markdown. C'est une bonne option. TinyMDE n'a pas assez d'options de personnalisation. Trix et Quill ne sont pas des éditeurs de markdown. Ce sont des éditeurs de texte enrichi donc ils ne produisent pas de markdown. Je vais opter pour EasyMDE. Pour l'instant.
Nous pouvons donc maintenant installer le package et l'utiliser. L'utilisation est un peu délicate. Étant un package uniquement côté client, nous ne pouvons pas l'exécuter ni l'importer côté serveur. Pour l'utiliser, nous allons l'importer dynamiquement dans un hook onMounted. onBeforeMount est encore mieux !
onMounted(async () => {
const EasyMDE = await import('easymde').then(m => m.default)
const easymde = new EasyMDE()
})Et ça fonctionne ? Oui, mais je pense que nous avons complètement oublié d'importer le style !

Je pense que nous avons oublié d'ajouter le style pour EasyMDE. Grâce à Vite et son chargeur CSS, nous pouvons importer directement le fichier CSS dans notre script.
<script lang="ts" setup>
import 'easymde/dist/easymde.min.css'
</script>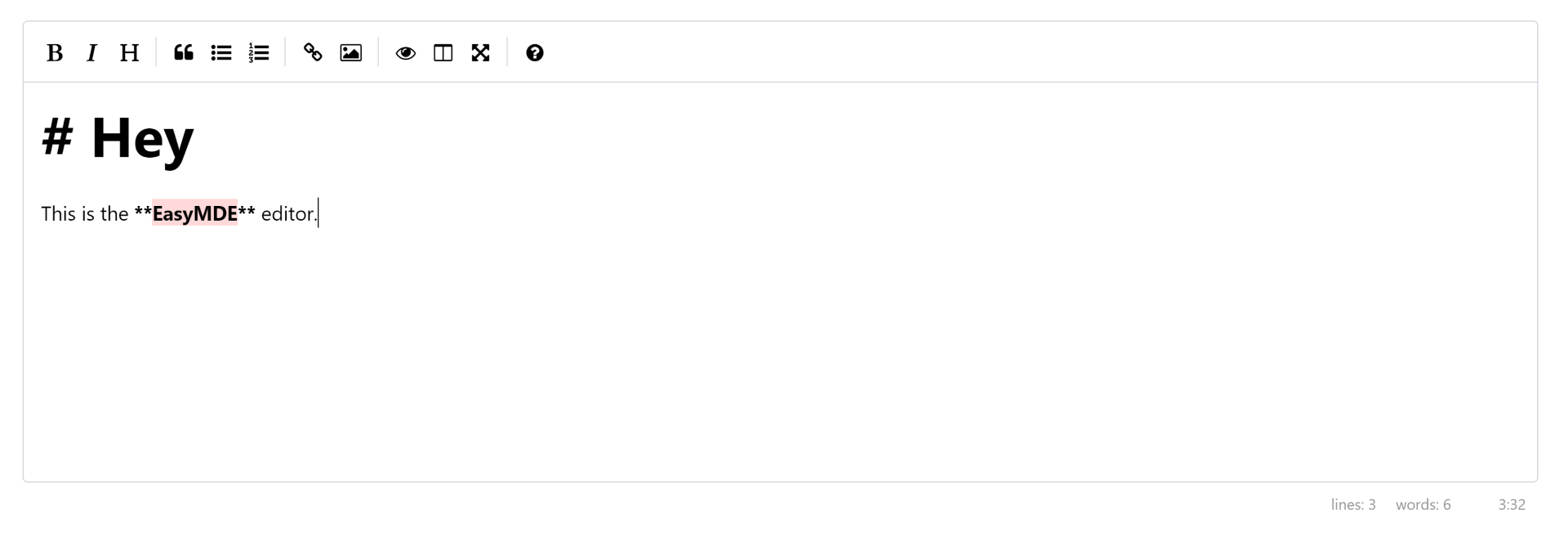
Ok, ce n'est pas parfait et j'aurai du travail à faire, tant sur les styles que sur les icônes. Mais c'est un bon début. La seule partie que je n'aime pas est le symbole markdown. Je préférerais ne pas les avoir parce que ce n'est pas convivial (tout le monde pourrait devoir créer un modèle).
Mais de toute façon, c'est un bon début et je peux maintenant facilement écouter les changements de l'éditeur et mettre à jour la description.
<script lang="ts" setup>
const description = ref<string>('')
onMounted(async () => {
const EasyMDE = await import('easymde').then(m => m.default)
const easymde = new EasyMDE()
easyMDE.codemirror.on('change', () => {
description.value = easyMDE.value()
})
})
</script>Maintenant, je peux envoyer la description au serveur et elle sera transformée en HTML !
Quelle est la prochaine étape pour le formulaire ?
Le formulaire est loin d'être terminé mais il progresse bien. Je vais ajouter le support pour les images et les modules dans le prochain stream.
Le projet Orion est presque prêt pour une version alpha et je suis impatient de voir comment la communauté l'utilisera et découvrir le contenu qu'ils partageront.
Remplacer l'éditeur Markdown
Cette partie a été réalisée hors-stream parce que je n'étais pas satisfait de l'éditeur EasyMDE mais je ne savais pas quoi faire.
Après y avoir réfléchi, j'ai réalisé que l'utilisation de Markdown, pour une simple description et qui peut être utilisée par des utilisateurs non techniques, n'est pas la meilleure idée. De plus, l'éditeur EasyMDE utilise CodeMirror qui est lent et beaucoup trop lourd pour un simple éditeur.
Maintenant que nous savons que l'éditeur EasyMDE n'est pas la meilleure solution pour nos besoins, nous devons en trouver un nouveau. Nous avons besoin d'un éditeur de texte enrichi simple et il y a deux options principales : Quill et Trix. Dans ce cas, Quill semble être plus simple donc je vais opter pour lui. Je ne détaillerai pas l'installation de Quill, c'est assez simple.
Comme Quill est un éditeur de texte enrichi, il ne génère pas de markdown mais du HTML. Je dois donc mettre à jour le point de terminaison pour stocker le HTML au lieu du markdown. Je dois également mettre à jour le schéma pour supprimer la colonne description et ajouter une colonne descriptionHTML.
Mise à jour du point de terminaison
Pourquoi dois-je mettre à jour le point de terminaison ? Quill renvoie du HTML déjà nettoyé, donc je pourrais le stocker directement dans la base de données. Oui mais non. Nous construisons une API et il est impossible de faire confiance au client, même à notre propre client. N'importe qui peut modifier le HTML ou utiliser un client HTTP pour envoyer une requête au serveur avec du HTML malveillant. Je dois donc nettoyer le HTML sur le serveur.
Par exemple, voici du HTML malveillant :
<p> Bonjour le monde ! </p>
<script> console.log('piraté') </script>Si vous stockez ce HTML dans la base de données et l'affichez en utilisant la directive v-html, chaque utilisateur qui verra la page exécutera le script. C'est un vrai problème de sécurité. Nous ne pouvons pas utiliser parce que Vue échappera le HTML donc nettoyer notre contenu est la seule solution.
Je vais utiliser le paquet sanitize-html pour nettoyer le HTML. Après avoir nettoyé avec ce paquet, le HTML sera :
<p> Bonjour le monde ! </p>C'est parfait !
await useDrizzle().insert(tables.templates).values({
description: body.description ? sanitizeHtml(body.description) : null,
})La fonction sanitizeHtml est l'exportation par défaut du paquet sanitize-html. Facile, non ?
Mise à jour du schéma
Maintenant, je dois mettre à jour le schéma pour supprimer la colonne descriptionHTML puisque la description est maintenant par défaut en HTML. Il est important de savoir que si l'utilisateur doit modifier son modèle, le HTML sera utilisé par l'éditeur Quill.
export const templates = sqliteTable('templates', {
description: text('description'),
descriptionHTML: text('description_html'),
})Mise à jour de l'interface utilisateur
L'utilisation de Quill n'est pas si différente de EasyMDE. Je charge paresseusement le paquet Quill, crée une nouvelle instance de celui-ci et écoute les changements. Je n'oublie pas d'importer le fichier CSS.
<script lang="ts" setup>
import 'quill/dist/quill.snow.css'
onBeforeMount(async () => {
const Quill = await import('quill').then(m => m.default)
quill.value = new Quill('#editor', {
theme: 'snow',
})
quill.value?.on('text-change', (_, __, source) => {
state.description = quill.value?.root.innerHTML ?? ''
})
})
</script>
<template>
<div id="editor" />
</template>Bien sûr, je dois ajouter quelques styles personnalisés à l'éditeur pour qu'il s'intègre plus naturellement dans le design.
Une dernière chose. J'utilise ceci dans un formulaire Nuxt UI. Dans ce formulaire, chaque élément est validé par rapport au schéma. Cela me permet d'afficher un message d'erreur si la description est vide ou trop longue. Le problème est que ce n'est pas intégré dans l'éditeur Quill, il ne déclenche aucune validation. Grâce à l'API du formulaire Nuxt UI, je peux facilement valider le contenu de l'éditeur Quill à chaque changement.
<script lang="ts" setup>
const form = ref()
onBeforeMount(async () => {
quill.value?.on('text-change', (_, __, source) => {
state.description = quill.value?.root.innerHTML ?? ''
form.value.validate('description', { silent: true })
})
})
</script>
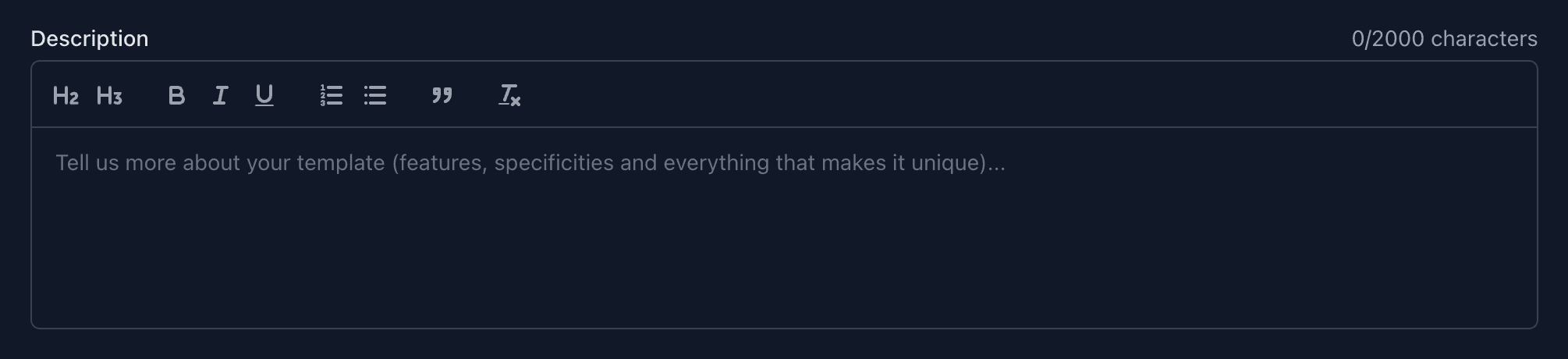
<template>
<UFormGroup
label="Description"
name="description"
:hint="`${state.description?.length || 0}/2000 characters`"
>
<div id="editor" />
</UFormGroup>
</template>Maintenant, l'éditeur Quill est complètement intégré dans le formulaire et un message d'erreur s'affichera si la description est vide ou trop longue.
Conclusion
Je suis vraiment content de ce changement. Depuis des années, je me demandais comment installer et utiliser un éditeur de texte enrichi et maintenant je sais. Vous pouvez utiliser le markdown pour les utilisateurs techniques, le parser sur le serveur et stocker le HTML pour simplifier une obtention, ou utiliser un éditeur de texte enrichi pour les utilisateurs non techniques et nettoyer le HTML sur le serveur. C'est une bonne leçon pour moi et j'espère qu'elle vous sera utile.
Ajout de modules au formulaire de modèle

Orion est une application full-stack construite avec Nuxt et développée en direct sur Twitch. Vous pouvez voir le replay sur YouTube et le code source est open-source sur GitHub.
Pendant ce live stream, j'ai ajouté la possibilité d'ajouter des modules à un modèle dans le formulaire. Cette fonctionnalité est importante car elle permettra aux utilisateurs de filtrer les modèles par modules.
J'ai choisi de le faire dans un stream séparé car c'est une relation de plusieurs à plusieurs et un peu plus complexe que les autres parties. Je m'attendais à le faire en 1 heure, mais cela m'a pris 2 heures avec l'aide du chat. En effet, j'étais bloqué sur la requête SQL pour récupérer un modèle peuplé avec ses modules, et la documentation de Drizzle n'était pas claire à ce sujet.
Plongeons dans le code et comprenons comment fonctionne le concept des relations ORM de Drizzle.
Schéma
Le créateur peut ajouter plusieurs modules à un modèle. En même temps, un module peut être utilisé par plusieurs modèles. La relation est une relation de plusieurs à plusieurs. Pour gérer cela, je dois créer une nouvelle table, appelée table de pivot, pour stocker la relation entre les modèles et les modules. Elle agit comme un lien entre les deux tables pour les connecter. Nous utilisons une table de pivot au lieu d'un tableau de modules dans le modèle parce que c'est plus efficace et c'est la façon SQL de le faire.

Le schéma est simplifié pour montrer uniquement la relation entre les modèles et les modules. À partir de la table templates, vous pouvez récupérer tous les modules associés et inversement grâce à la table templates_modules.
export const templates = sqliteTable('templates', {
id: integer('id').primaryKey({ autoIncrement: true }),
title: text('title').notNull(),
})
export const modules = sqliteTable('modules', {
id: integer('id').primaryKey({ autoIncrement: true }),
name: text('name').notNull().unique(),
})
export const modulesToTemplates = sqliteTable('modulesToTemplates', {
moduleId: integer('module_id').notNull().references(() => modules.id),
templateId: integer('template_id').notNull().references(() => templates.id),
})Formulaire de modules
Dans cette partie, je vais ajouter les modules au formulaire, du côté client au côté serveur.
Ajout de modules au modèle
Dans l'interface utilisateur, gérer les modules est assez simple. Je récupère les modules du serveur et les affiche dans un USelectMenu avec une prop multiple.
<script lang="ts" setup>
const { data: modules } = await useFetch('/api/modules', {
deep: false,
default: () => [],
})
</script>
<template>
<USelectMenu
:options="modules"
multiple
value-attribute="id"
option-attribute="name"
/>
</template>Validation des modules
Dans le validateur, j'ajoute un nouveau champ moduleIds qui vérifie que les modules sont un tableau d'entiers.
import { array, number, object, string } from 'zod'
export const createTemplateValidator = object({
title: string({ message: 'Requis' }),
moduleIds: array(number()).max(6, { message: 'Max 6 modules' }).optional(),
})J'ai arbitrairement fixé le nombre maximum de modules à 6. C'est un nombre que je pense suffisant pour un modèle.
Enregistrement des modules
Enfin, je mets à jour le point de terminaison pour enregistrer le modèle et les modules associés. Je commence par enregistrer le modèle, puis les modules dans la table de pivot.
import { createTemplateValidator } from '~/utils/validators'
export default defineEventHandler(async (event) => {
const { user } = await requireUserSession(event)
const body = await readValidatedBody(event, createTemplateValidator.parse)
const [template] = await useDrizzle().insert(tables.templates).values({
title: body.title,
}).returning({
id: tables.templates.id,
})
if (body.moduleIds)
await useDrizzle().insert(tables.modulesToTemplates).values(body.moduleIds.map(id => ({ moduleId: id, templateId: template.id }))).execute()
return sendNoContent(event, 201)
})Je dois admettre que je ne suis pas très confiant avec cette partie. Je devrai vérifier s'il y a une meilleure façon de le faire (en utilisant une transaction ou une fonctionnalité intégrée de Drizzle).
Remplir le modèle avec des modules
C'est là que les choses deviennent difficiles.
Au départ, j'avais une requête SQL personnalisée qui joignait la table templates, la table users et la table categories. Vous pouvez en savoir plus à ce sujet dans la partie précédente.
Pour lier la table modules, j'ai essayé d'ajouter une jointure avec la table modulesToTemplates puis la table modules. Le problème que je rencontre est comment grouper les modules par modèle pour produire un tableau de modules pour chaque modèle.
Quelque chose comme :
{
"id": 1,
"title": "Mon modèle",
"modules": [
{ "id": 1, "name": "Module 1" },
{ "id": 2, "name": "Module 2" }
]
}J'ai trouvé la fonction SQLite group_concat qui peut être utilisée pour concaténer les modules. J'étais un peu déçu de devoir le faire manuellement car Drizzle se présente comme un ORM. Je m'attendais à avoir un moyen de le faire facilement.
MAIS, le chat Twitch est venu à la rescousse et m'a suggéré d'utiliser la clé with de la méthode findMany. J'ai essayé, et cela n'a pas vraiment fonctionné. Cloudflare se plaignait d'une relation manquante. J'étais un peu perdu.
J'ai fini par lire attentivement la documentation sur la page de la relation de plusieurs à plusieurs, et j'ai compris que je devais définir explicitement chaque relation entre chaque table. En d'autres termes, je dois dire à Drizzle comment joindre les tables. Un modèle a plusieurs modules en utilisant la table modulesToTemplates. Un module a plusieurs modèles en utilisant la table modulesToTemplates. C'est ainsi que l'on définit la relation de plusieurs à plusieurs.
// Un modèle a une relation de plusieurs à plusieurs
export const templatesRelations = relations(templates, ({ one, many }) => ({
// Lié à la table de pivot et non directement à la table des modules
modules: many(modulesToTemplates),
}))
// La table de pivot a 2 relations
export const modulesToTemplatesRelations = relations(modulesToTemplates, ({ one }) => ({
module: one(modules, {
fields: [modulesToTemplates.moduleId],
references: [modules.id],
}),
template: one(templates, {
fields: [modulesToTemplates.templateId],
references: [templates.id],
}),
}))
// Un module a une relation de plusieurs à plusieurs
export const modulesRelations = relations(modules, ({ one, many }) => ({
// Lié à la table de pivot et non directement à la table des modèles
templates: many(modulesToTemplates),
}))Cette partie est super importante. Dans un ORM comme Lucid, l'utilisation d'une table de pivot est transparente. Avec Drizzle, vous devez définir la relation entre chaque table. C'est un peu plus verbeux, mais c'est aussi plus explicite.
Enfin, je peux mettre à jour le point de terminaison pour récupérer les modèles avec leurs modules :
export default defineEventHandler(async () => {
const templates = await useDrizzle().query.templates.findMany({
with: {
category: true,
creator: true,
modules: {
with: {
module: true
},
},
},
})
return templates
})L'utilisation de with, une fois que tout est correctement défini, rend les choses tellement plus faciles ; j'adore vraiment ça.
Conclusion
Dans mon esprit, cette partie était facile, et en 30 minutes, c'était fait. J'avais déjà fait quelque chose de similaire en utilisant Lucid d'Adonis. En réalité, ce n'était pas vraiment difficile, mais trouver la bonne partie de la documentation de Drizzle puis la comprendre était bien plus difficile que prévu. Cela est largement dû au fait que Drizzle n'abstrait pas SQL mais agit comme un petit wrapper, et tout doit être explicite.
Je suis heureux de l'avoir fait, j'ai beaucoup appris, et un grand merci au chat pour leur aide.

Merci de me lire ! Je m'appelle Estéban, et j'adore écrire sur le développement web et le parcours humain qui l'entoure.
Je code depuis plusieurs années maintenant, et j'apprends encore de nouvelles choses chaque jour. J'aime partager mes connaissances avec les autres, car j'aurais aimé avoir accès à des ressources aussi claires et complètes lorsque j'ai commencé à apprendre la programmation.
Si vous avez des questions ou souhaitez discuter, n'hésitez pas à commenter ci-dessous ou à me contacter sur Bluesky, X, et LinkedIn.
J'espère que vous avez apprécié cet article et appris quelque chose de nouveau. N'hésitez pas à le partager avec vos amis ou sur les réseaux sociaux, et laissez un commentaire ou une réaction ci-dessous, cela me ferait très plaisir ! Si vous souhaitez soutenir mon travail, vous pouvez me sponsoriser sur GitHub !
Discussions
Ajouter un commentaire
Vous devez être connecté pour accéder à cette fonctionnalité.